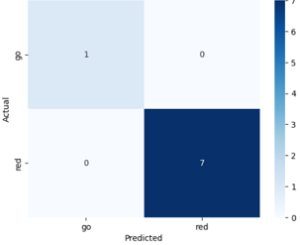
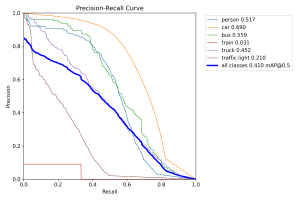
Unfortunately, I wasn’t able to make much progress on this end. So far, I attempted switching the label mapping of the bdd100k dataset, trying to fine-tune different versions of the YOLOv8 models, and tuning the hyperparameters slightly, but they all had exactly the same outcome of the model performing extremely poorly on held out data. As to why this is happening, I am still very lost, and have had little luck figuring this out.
However, since we remain interested in having a small suite of object detection models to test, I decided to try to find some more YOLO variants to evaluate while the fine-tuning portion is being solved. Specifically, I decided to evaluate YOLOv12 and Baidu’s RT-DETR models, both compatible with my current pipeline for pedestrian object detection. The YOLOv12 model architecture introduces an attention mechanism for processing large receptive fields for objects more effectively, and the RT-DETR model takes inspiration from a Vision-Transformer architecture to efficiently process multiscale features in the input.
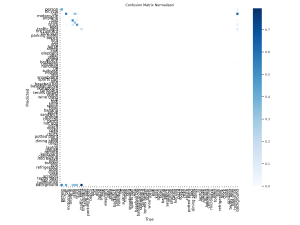
It appears that despite being more advanced/larger models, these models actually don’t do much better than the original YOLOv8 models I was working with. Here are the prediction confusion matrices for the YOLOv12 and RT-DETR models, respectively:
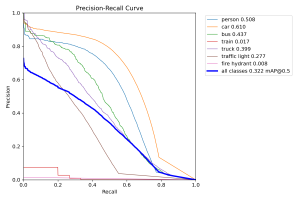
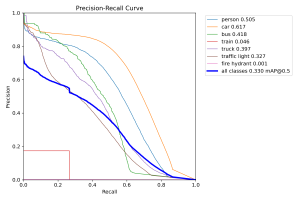
This suggests that it’s possible that these object detection models are hitting the limit of performance on this particular out of distribution dataset, and that testing these out in the real world might have similar performance across models as well.
Currently, I am a bit behind schedule as I was unable to fix the fine-tuning issues, and subsequently was not able to make much progress on the integration components with the navigation submodules.
For this week, I will temporarily shelve the fine-tuning implementation debugging in favor of implementing the transitions between the object detection and navigation submodules. Specifically, I plan on beginning to handle the miscellaneous code that will be required to pass control between our modules.