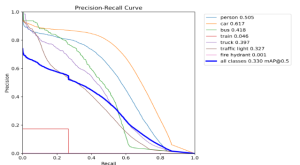
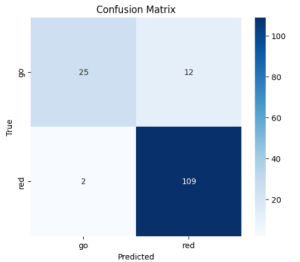
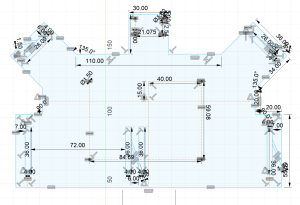
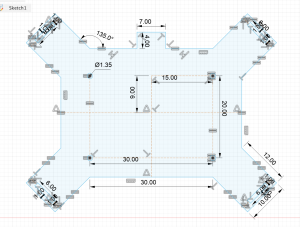
Currently, the most significant risk to the project is obtaining high-quality data to use for training our models. This is crucial, as no amount of hyperparameter optimization and tuning will overcome a lack of high-quality and well-labeled data. The images we require are rather specific, such as obstacles in a crosswalk from a pedestrian’s perspective and images of the pedestrian traffic light taken from the sidewalk. We are managing this risk by obtaining data from a variety of sources, such as online datasets, Google Images and Google Maps, and also real-world images. If this does not work, our contingency plan is to perhaps adjust the purpose of our model so that it does not require such specific data.
As outlined in William’s status report for this week, a few updates have been made to the hardware components. First, an additional IMU module is needed for accurate user heading. The FOV of the camera ordered was reduced from 175º (D) to 105º (D), as we were concerned about image distortion and extraneous data from having such a wide FOV. We chose 105º after some comparisons made using an actual camera to better visualize each FOV’s effective viewport. Having the Jetson Orin Nano on hand also allowed us to realize that additional components were needed to have audio output (no 3.5mm jack was present) and to make the power supply portable (the type-c port does not supply power to the board). These changes did not require any additional cost incurred by incompatible parts, as we have been very careful to ensure compatibility before actually ordering.
Our schedule remains essentially the same as before. For the hardware side, all the system’s critical components will arrive on time to stay on schedule. For the software side, our object detection model development is slightly behind schedule as mentioned in Andrew’s status report for 2/15. We anticipate having several versions of models ready for testing by the end of next week, and will be able to hopefully implement code to integrate it into our broader setup.
We will now go over the week 2 specific status report questions. A was written by William, B was written by Max and C was written by Andrew.
Part A. The Self-Driving Human is a project that is designed to address the safety and well-being of visually impaired pedestrians, both in a physiological and psychological sense. Crossing the street as a visually impaired person is both scary and dangerous. Traditional aids can be absent or inconsistent. Our project provides real-time audio guidance that helps the user cross the road safely, detect walk signals, avoid obstacles, and stay on the crosswalk. Because it is an independent navigation aid, it provides the user with self-sufficiency, as they are not reliant on crosswalk aids being maintained to cross the road. This self-sufficiency is an aspect of welfare, as the ability to move freely and confidently is a basic need. Ideally, our project works to create a more accessible and inclusive environment.
Part B. From a social perspective, the helmet will improve accessibility and inclusivity for visually impaired people and allow them to participate more fully in public life. There are some cities where pedestrian infrastructure is less friendly and accommodating, so this helmet would enable users to still cross streets safely. Economically, this helmet could reduce the need for expensive public infrastructure changes. Politically, solutions like this for the visually impaired can help increase awareness of the need for accessible infrastructure.
Part C. The traditional method of assisted street crossing/pedestrian navigation for the visually impaired involves expensive solutions such as guide dogs. While there is a significant supply of assistance, these methods might not be broadly accessible to consumers in need of them with regard to economic concerns. As such, we envision our project to serve as a first step in presenting an economically viable solution, able to be engineered with a concrete budget. As all of the navigation and feedback capabilities will be built directly into our device and will have been appropriately developed before porting them to the hardware, we anticipate that our (relatively) lightweight technology can increase the accessibility of visually impaired navigation assistance on a budget, as the development and distribution our project can be scaled with the availability of hardware, helping resolve consumption patterns.