
This week I worked on writing the main program that would run the entire system, which involved integrating the various ML submodules. I have tested that both models work when running together. All we have left to do is add the audio component, which simply involves calling a Python library to connect the earbuds and play an audio file in certain if/else blocks in our code. Other than that, the device is pretty much in a finalized state.
Max Tang Status Report 4/19/2025
This week I worked on the final integration of the walk sign image classification model into the board and docker environment. We first further optimized the walk sign model. I trained it on two different datasets: one that included a lot of non-crosswalk images labeled as “don’t walk”, and one that only included crosswalk images. I also implemented the code logic for transitioning from walk sign image classification to cross walk object detection. Initially, the model worked fine on the board, but uploading the other object detection model, we realized there were Python dependency conflicts. This is still currently an issue, as there have been challenges in trying to convert the tensorflow model to a pytorch model. One attempt was to change the walk sign model from a tensorflow model to a pytorch model. This involved first saving the model in the .tf format, and then converting it to .onnx using (python -m tf2onnx.convert –saved-model walksignmodel –output walksignmodel.onnx), and then converting that to .pt. However, this has had many other python dependency issues with the onnx libraries too. My plan for this weekend is to resolve this issue as soon as possible.
Update on 4/20/2025: The pytorch issue has been resolved, see team status report for update.
Max Tang’s Status Report for 4/12/2025
Last week, we conducted a live test of the walk sign image classifier using the initial model. This involved running the model on the Jetson and feeding it images captured by the camera once every 2 seconds. By also saving the image that was being fed into the model, I could then later view the image on my computer and see exactly what the model was seeing. The performance during the live test was not great and the model frequently predicted “GO” and only rarely predicted “RED”. To try and fix this, we collected 400 more images using the same camera and retrained the model. I re-evaluated the performance with a test dataset and it seems to be better now, but I still need to conduct more field tests and then likely repeat this process if it’s not performing well enough. I also need to work on implementing the rest of the control logic for switching from the walk sign classification to the object detection process.


Max Tang’s Status Report for 03/29/2025
This week I worked on getting the walk sign classification model uploaded onto the Jetson Orin Nano. The Jetson can natively run Python code and can run a Jetson-optimized version of TensorFlow, which we can download as a whl file and install on the board. The only Python libraries needed for the ResNet model are numpy and tensorflow, specifically keras, and both of these can run on the Jetson. The model itself can be saved as a .h5 model after being trained in Google Colab, and can be uploaded to the Jetson. Then the Python program can simply load the model with the help of keras and perform inferencing. The code itself is very simple: we simply import the libraries, load the model, and then it is ready to make predictions. The model itself is 98 MB, which fits comfortably onto the Jetson. The tensorflow library is less than 2 GB and numpy is around 20 MB, so they should fit as well.
The challenge now is getting the video frames as input. Currently we can get the camera working with the Jetson and stream the video on a connected monitor, but this is done through the command line and we need to figure out how to capture frames and give it to the model as input. Either the model connects to the camera through some interface, or some other submodule saves frames into the local file system for the model to then take as input, which is how it currently works.
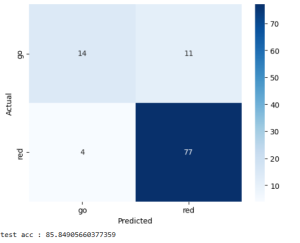
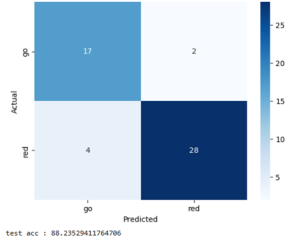
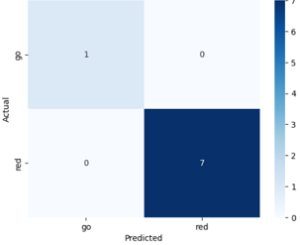
The model is also now performing better on the same testing dataset from last week’s status report. I’m not sure how this happened, since I did not make any changes to the model’s architecture or the training dataset. However, the false negative rate decreased dramatically, as seen in this confusion matrix.
Max Tang’s Status Report for 3/22/2025
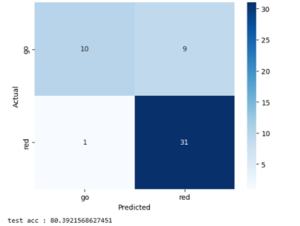
The walk sign image classification model is in a near-finalized state where I can begin to transition away from optimizing the model’s performance. Since last week, I performed some hyperparameter optimization and also tried adding some layers to the ResNet model to try and increase its performance. I tried changing the size of the dense linear layers, the number of epochs it was trained for, different activation functions, and additional linear and pooling layers. However, these did not seem to help as much as simply adding more training data that I’ve been continuously collecting. I also removed the validation dataset and divided its images amongst the training and testing datasets, since I did not find any real use to having a validation dataset and I benefited more from just having more data to train and test with. Current test accuracy is around 80%, which is not as high as desired. However, the good news is that most of the errors were when the model predicted “stop” when the image was “go”. This is much better than predicting “go” when the image is “stop”, and while I did not purposefully design the model to be more cautious when predicting “go” and this seemed to be a coincidence, it is something that I have realized that I could potentially add. This would not necessarily have to be a change to the model and could be done in some post-processing step instead.
The next step is implementing the logic that would take video input data and feed it into the model at some frequency and then return the result, using a sliding window for both the input and output. I plan to begin working on this next week.
Max Tang’s Status Report for 3/15/2025
Training the walk sign image classification model has had significant progress. The ResNet model is very easy to work with, and I have been addressing the initial overfitting from last week by training the model on a much more diverse dataset from multiple intersections around the city. I’ve developed the habit of always having my camera open when I get near intersections when I’m walking or commuting around Pittsburgh, and I have been able to get much more images. All I have to do is crop them and feed them into model. I have also been working on some hyperparameter optimization, such as the different layers and sizes. This has not really resulted in improved performance, but it’s possible that I can add more layers that will make it better. This will require some research to determine if layers like additional dense layers will help. By going into the open-source ResNet code, I can I think next week I want to have the model in a finalized state that I can being integrating it into the microcontroller. I think I will have to spend some time figuring out how to quantize the model to make it smaller next week.
Max Tang’s Status Report for 3/8/2025
This week I worked on training and tuning the walk sign image classification model. I made a major design change for this part of the system: instead of using a YOLO model that is trained for object detection, I decided to instead switch to an off-the-shelf ResNet model that I was able to fine tune with our own custom dataset. I initially thought that a YOLO model would be best since the system would need to find the walk sign signal box in an image and create a bounding box, but the issue is that this wouldn’t be able to classify the image as either a WALK or DON’T WALK. ResNet is just a convolutional neural network that can output labels, so as long as it is trained on enough high quality data, it should still be able to find the walk sign in an image. The training and evaluation is easily done in Google Colab:

More data needs to be collected to improve the model and increase its ability to generalize, as the current model is overfitting to the small dataset. Currently, finding high quality images of the WALK sign has been the main issue, as Google Maps tends to only have pictures of the DON’T WALK sign, and I can only take so many pictures of different WALK signs throughout the day. The good news is that retraining the model can be done very quickly, as the model is not that large so that it fits on the microcontroller. Now that I have the model finally working, I can focus my time next week on further data collection. Progress is still somewhat on schedule, but I will need to work on integrating this from my local machine onto the board soon.
Max Tang’s Status Report for 2/22/15
This week I finished collecting all of the pedestrian traffic light data and also began the process of training the YOLOv8 image classification model. I explored collecting data through different ways but ultimately gathered most of my images from Google Earth. I took screenshots at various intersections in Pittsburgh and I varied the zoom distance and angle of each traffic light to get a diverse dataset. I also made sure to find different environmental conditions such as sunny intersections versus shadier intersections. Initially I explored other ways of collecting data such as taking pictures with my phone, but this proved to be too inefficient, and it was too difficult to get different weather conditions and going to different intersections with different background settings (buildings vs. nature) was too hard. I also explored using generative AI to produce images but the models I tried were unable to create realistic images. I’m sure there are models capable of doing so, but I decided against this route. I also found a few images from existing datasets that I added to my dataset.
The next step was to label and process my data. This involved categorizing each image as either “stop” or “go”, which was done manually. The next step was to prepare it for the YOLOv8 model, which involved putting bounding boxes around each pedestrian traffic light box in each image. I did this using Roboflow, a web application that let me easily add bounding boxes and export it in a format that can be directly inputted into YOLOv8. Then it was simply a matter of installing YOLOv8 and running it in a Jupyter Notebook.
Progress was slightly behind due to the initial difficulties with data collection, but I had updated my Gantt chart to reflect this and am on schedule now. Next week I plan on tuning the YOLOv8 model to try and increase the accuracy on my validation dataset, which so far needs improvement.
Max Tang’s Status Report for 2/15/2025
This week I worked on compiling data for training the walk sign detection model. The model’s performance is only as good as the data that it is trained on, so I felt that it was important to get this step right. I spent a lot of time searching online for datasets of pedestrian traffic lights. However, I encountered significant challenges in finding datasets specific to American pedestrian traffic signals, which typically use a white pedestrian symbol for “Walk” and a red hand for “Don’t Walk.” The majority of publicly available datasets featured Chinese pedestrian signals that use a red pedestrian and green pedestrian symbol, which are not suitable for this model. I decided to instead compile my own dataset by scraping images from Google as well as Google maps. I will also augment this dataset with real world images, which I will begin next week. This progress so far is on schedule, perhaps a little behind. The lack of existing American datasets set my back a little, so I will need to expedite the data collection. Next week I hope to have a fully labeled dataset with multiple angles and lighting situations. This should be ready for model training, which will be the next step in the walk sign detection section.
Max Tang’s Status Report for 2/8/2025
This week I presented our group’s initial proposal presentation. The presentation went well, and I received many thought-provoking questions that have helped me realize that there were some aspects to our design that we have not considered, such as intersections that have multiple sidewalks. I began searching for suitable models that we can use to create our walk sign image classification model. One of these is an off-the-shelf YOLOv8 model that we can simply fine tune on walk sign images. Another potential solution I found is to gather as many images of walk signs as possible, as a combination of existing online datasets and self-taken images, and upload them to Edge Impulse. Then I can use Edge Impulse’s image classification model, which would be great for our project since Edge Impulse has a feature that lets you create quantized models, which use smaller data types for storing parameters and reduces the total memory required.
Progress is still on schedule. We allocated ourselves a large chunk of time for researching and making the model, and I believe that picking a suitable model at the beginning will help save time tuning and testing later. Next week I hope to be able to start the training and initial testing against validation datasets. This will give ample time for iteration if further improvements are required, which is very likely.