
This week I worked on training and tuning the walk sign image classification model. I made a major design change for this part of the system: instead of using a YOLO model that is trained for object detection, I decided to instead switch to an off-the-shelf ResNet model that I was able to fine tune with our own custom dataset. I initially thought that a YOLO model would be best since the system would need to find the walk sign signal box in an image and create a bounding box, but the issue is that this wouldn’t be able to classify the image as either a WALK or DON’T WALK. ResNet is just a convolutional neural network that can output labels, so as long as it is trained on enough high quality data, it should still be able to find the walk sign in an image. The training and evaluation is easily done in Google Colab:

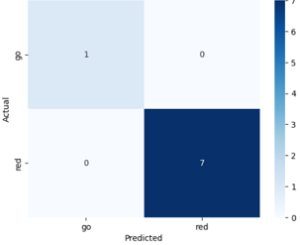
More data needs to be collected to improve the model and increase its ability to generalize, as the current model is overfitting to the small dataset. Currently, finding high quality images of the WALK sign has been the main issue, as Google Maps tends to only have pictures of the DON’T WALK sign, and I can only take so many pictures of different WALK signs throughout the day. The good news is that retraining the model can be done very quickly, as the model is not that large so that it fits on the microcontroller. Now that I have the model finally working, I can focus my time next week on further data collection. Progress is still somewhat on schedule, but I will need to work on integrating this from my local machine onto the board soon.