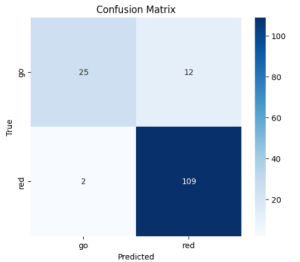
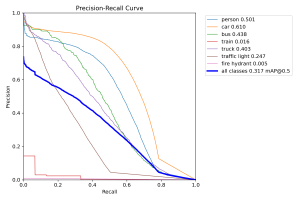
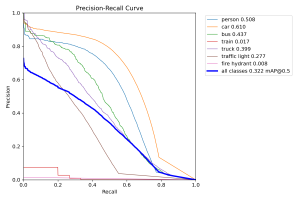
A change was made to the existing design – specifically, the machine learning model used in the walk sign subsystem was changed from a YOLO object detection model to a ResNet image classification model. This is because the subsystem needs be able to actually classify images as either containing a WALK sign or DON’T WALK sign, so an object detection model would not suffice. No costs were incurred by this change other than the time spent adding bounding boxes to the collected dataset. One risk is the performance of the walk sign image classification model when evaluated in the real world. It is possible that images captured by the camera when mounted on the helmet are different (blurrier, taller angle, etc.) than the images the model is trained on. This can definitely affect its performance, but now that the camera has arrived, we can begin testing this and adjust our dataset accordingly.
Part A (written by Max): The target demographic of our product is the visually impaired pedestrian population, but the accessibility of pedestrian crosswalks around the world varies greatly across countries, cities, and even neighborhoods within a single city. It is common to see sidewalks with tactile bumps, pedestrian signals that announce the WALK sign and the name of the street, and other accessibility features in densely populated downtowns. However, sidewalks in rural neighborhoods or less developed countries often do not have any of these features. The benefit of the Self-Driving Human is that it would work at any crosswalk that has the signal indicator. As long as the camera can detect the walk sign, then the helmet is able to run the walk sign classification phase and navigation phases without any issues. Another global factor is the different symbols used to indicate WALK and DON’T WALK. For example, Asian countries often use an image of a green man to indicate WALK, while U.S. crosswalks use a white man. This can only be solved by training the model on country-specific datasets, which might not be as readily available in some parts of the world.
Part B (written by William): The Self-Driving Human has the potential to influence cultural factors by reshaping how society views assistive technology for the visually impaired. In particular, our project would increase mobility and reduce reliance on caregivers for its users. This can lead to cultural benefits like increased participation in certain social events as the user gains more autonomy. Ideally, this would lead to greater inclusivity in city design and social interactions. Additionally, our project could promote a standardized form of audio-based navigation, influencing positive expectations about accessible infrastructure and design. We hope this pushes for broader adoption of assistive technology-driven solutions, which could result in the development of even more inclusive and accessible technologies.
Part C (written by Andrew): The smart hat for visually impaired pedestrians addresses a critical need for independent and safe navigation while keeping key environmental factors in mind. By utilizing computer vision and GPS-based obstacle detection, the device minimizes reliance on physical infrastructure such as paving and audio signals, which may be unavailable or poorly maintained in certain areas. This reduces the dependency on city-wide accessibility upgrades, making the solution more scalable and effective across diverse environments. Additionally, by incorporating on-device processing, the system reduces the need for constant cloud connectivity, thereby lowering energy consumption and emissions associated with remote data processing. Finally, by enabling visually impaired individuals to navigate their surroundings independently, the device supports inclusive urban mobility while addressing environmental sustainability in its design and implementation.