
Last week, we managed to get both the object detection model and walk sign model onto the board. Due to make sure that the object detection model could use the GPU and decrease the inference time, we had to create a docker container for it to run in. However, due to Python dependency issues with tensorflow and pytorch, we are currently trying to change the walk sign image classification model to only use pytorch. We have tried a variety of methods such as converting a .h5 tensorflow model to a .pth pyotrch model, and also just rewriting everything using pytorch, but both have had issues. We are still currently exploring solutions to this problem.
Regarding hardware, we have finally mounted all our components to the chest mount. The power bank also arrived, which fits nicely into a fanny pack. We have tested running our system fully attached to a person, and it works as expected. The device is comfortable, and does not impede user motion or weigh too much. We are still improving the mount, but it’s in a very good state right now.
Update on 4/20/2025: Regarding the issue with converting the model from tensorflow to pytorch, we have successfully recreated the model in pytorch. We now have 3 different models trained on the much larger dataset collected from last week, using resnet 34, 101, and 152. The performance and confusion matrix for each are pretty similar. This is the confusion matrix for the resnet 152 model:
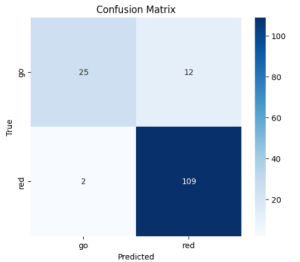
The test accuracy is 90.54%, but it’s possible that the class imbalance is skewing this accuracy. In any case, it’s better for the model to be more cautious when predicting “walk” than “don’t walk”, and we see that the error rate for the “don’t walk” class is very low.