
I am using TensorRT and Onnx packages to perform the quantization on the YOLO models, which I found online was the best method for quantizing ML models for Edge AI computing, due to the fact that this method results in the fastest speedups while shrinking the models appropriately. However, this process was pretty difficult as there are a lot of hardware specific issues I ran into in this process. Specifically, the process of quantizing using these packages involves at lot of under the hood implementation assumptions about how the layers are implemented and whether or not they are fuse-able, which is a key part of the process.
I did end up figuring it out, and ran some evaluations on the YOLOv12 model to see how performance changes with quantization:

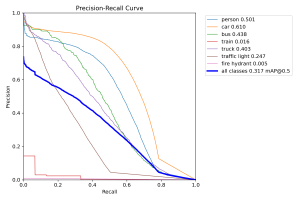
Visually inspecting the prediction-labelled images and PR curve as well as the normalized confusion matrix, just like before, it generally appears that there isn’t much difference in performance with the base, un-quantized model, which is great news. This implies that we can compress our models in this way without sacrificing performance, which was the primary concern
Currently, I am about on schedule with regards to ML model development, but slightly behind on integration/testing the navigation components.
For this week, in tandem with the demos we are scheduled for, I plan on getting into the details of integration testing. I also would be interesting in benchmarking any inference speedups associated with the quantization, both in my development environment and on the Jetson itself in a formal testing setup.