
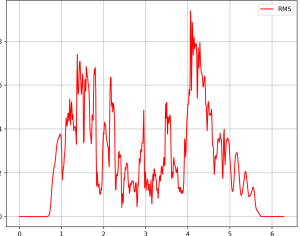
This week has been continuing to fine tune the algorithm for slurred notes and rests. We made the switch last week to STE from RMS and we saw better results as it kept the near zero values closer to zero, however with slurred notes the values still do not get close enough.
I created an algorithm that would look through the segments from the original algorithm and if it has any times, then it would “flag” the segment as a possible slurred note. Then I would check for pitch changes. I first used spectrogram but found that iw would miss some notes or incorrectly identify where the notes actually change, so I switched to using STFT and having a ratio varying based on BPM to detect smaller note changes with faster tempos with better success. Here is a picture of using the spectrogram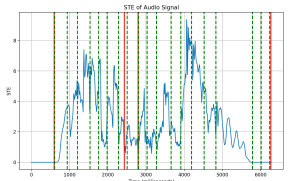
and using the STFT
While there are still some inaccuracies, it is much better than before. Currently working on fine tuning the rest detections as right now it has a tendency to over detect rests. Also looking into using CNNs for classification of slurred notes
While implementing this project, I learned more about signal processing and how some things are much easier to identify manually/visually than coding it up. Additionally, reading up on how much people research into identifying segmentations in music and how different types of instrument can add to more slurs as they tend to be more legato. For this project, I needed new tools on identifying new notes like using STFT and STE. To learn more about these, I would read research papers from other projects and universities on how they approach it and tried to combine aspects of them to get a better working algorithm.
 (forgot to change label for the line, but this is a graph for STE – this was taken using audio from a student in the school of music)
(forgot to change label for the line, but this is a graph for STE – this was taken using audio from a student in the school of music)






