
This week, we as a collective worked on creating a way to store past transcriptions using SQLite on our website as well as let people add, edit, and change anything from the original transcription that was generated. We believed that this followed the ebbs and flows of composition better and we wanted to mimic that. In addition to that, we are now focusing on fine tuning and testing our program further as well as working on some of the final deliverables, like the presentation and the poster.
Unit Tests:
Rhythm Detection/Audio Segmentation: Testing this on different BPM compositions of Twinkle Twinkle Little Star, using songs with tied notes like Ten Little Monkeys and compositions from the school of music, and compositions with rests in them like Hot Cross Buns and additional songs from the school of music.
Overall System Tests: We tested this project on varying difficulty of songs such as easy songs like nursery rhymes (hot cross buns, ten little monkeys, twinkle twinkle little star, etc) and scales, intermediate difficult songs from youtube as well as our team members playing (Telemann – 6 Sonatas for two flutes Op. 2 – no. 2 in E minor TWV 40:102- I. Largo, Mozart – Sonata No. 8 in F major, K. 13 – Minuetto I and II, etc) and more difficult sections like composition from the school of music.
Findings and Design Changes: From these varying songs, we realized that our program struggled more with higher octaves as the filter would accidentally cut off those frequencies, slurred notes (as it wouldn’t see it as the onset of a new note), and rests (especially when trying to differentiate moments of taking a breath from actual rests). These led us to tweaking how we defined a new note to create a segmentation and the boundaries for our filter.
Data Obtained:
| Latency | Rhythm Accuracy | Pitch Accuracy | |
| Scale 1: F Major Scale | 10.08 secs | 100% | 100% |
| Scale 2: F Major Scale W/ Ties | 12.57 secs | 97% | 95% |
| Simple 1: Full Twinkle Twinkle Little Star | 13.09 secs | 100% | 100% |
| Simple 2: Ten Little Monkeys | 14.46 secs | 93% | 100% |
| Simple 3: Hot Cross Buns | 11.78 secs | 91% | 100% |
| Latency | Rhythm Accuracy | Pitch Accuracy | |
| Intermediate 1: Telemann – 6 Sonatas for two flutes Op. 2 – no. 2 in E minor TWV 40:102 | 15.16 secs | 90% | 100% |
| Intermediate 2: I. Largo, Mozart – Sonata No. 8 in F major, K. 13 – Minuetto I and II | 16.39 secs | 87% | 97% |
| Hard 1: Phoebe SOM Composition | 10.99 secs | 91.5% | 100% |
| Hard 2: Olivia SOM Composition | 12.11 secs | 93% | 100% |

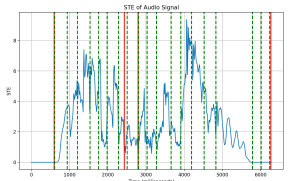

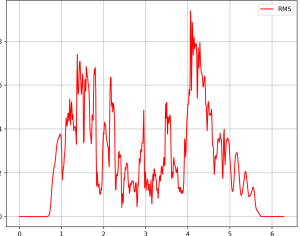 (forgot to change label for the line, but this is a graph for STE – this was taken using audio from a student in the school of music)
(forgot to change label for the line, but this is a graph for STE – this was taken using audio from a student in the school of music)





