
Talay’s Status Report for 4/26
This week, I worked with the team to do some final fine-tuning of the different components of our project. We first tried to fine-tune the magnetometer (compass) since that was the least robust part of our hardware system. The compass was able to give orientation direction pretty well when the chip is always parallel to the floor. We wrote a mathematical equation to calculate the offset of the compass reading from true north and combined this with A*’s given direction to find the final direction to buzz the haptics at. We fine-tuned the compass as best we could but our final design would require the compass to be parallel to the floor always. If the compass tilted forwards or backwards, some readings may be slightly off. Other parts of our system were quite robust at this point when we tested it in Hammerschlag Hall. We received our final haptic sensors and added them to our system. Our system is complete with the setup in Hammerschlag Hall but moving to a new location would require some calibration and a bit of fine-tuning. We are also in the progress of integrating our entire system to a belt form factor.
This week we fine-tuned our system by doing more tests on it. Our CV stack is already quite robust, so we mainly tested the navigation, magnetometer, and haptics in the captured frame. We placed different configurations of obstacles in the room and had the person hold the entire circuit and navigate around the room. We tweaked the vibration patterns so that it would always buzz so the blind person knows where to go. We handled special error cases such as if the person was detected to be inside an obstacle. In those cases we would just vibrate the last known direction and make sure the person exits the obstacle first. We tested our entire system until we were quite sure this would work well.
Our progress is on schedule but we would still need to work hard this next week to complete all the deliverables.
Next week, we hope to finish integrating our product into the belt form factor. We would also need to to calibrate and set up the demo environment before the actual demo day. We also have the project video and final report coming up, so we would start working on that soon. Our project poster is in progress and will be completed by Monday.
Team Status Report for 4/19
The most significant risk that could jeopardize the success of our project is if one of the components break. Since our design requires a lot of components and we only have one of each, breaking one of them could jeopardize the functionality of our project. Each of these components are fully working right now, but some of them seem quite fragile with wires hanging loose. The way we design our final form factor for the belt will be crucial so that components are embedded securely onto it. We don’t want a belt that would have our components hanging loose or falling while the user is walking around. Since all the other components are fixed in place, the belt would be the most fragile part of our design and would need careful planning.
The only changes made to the existing design of the system is to do processing on a separate node instead of the Jetson. The Jetson does not have enough compute to segment the image, so we will be offloading that compute to the laptop instead.
Talay’s Status Report for 4/19
This week, I first worked on setting up the magnetometer with Kevin. Even though we bought a HMC5883L, we actually received a QMC5883L, which is slightly different. We were able to find a GitHub repository that allowed us to set up the magnetometer and have it output the orientation of the person relatively well.
Next, we worked to integrate the entire system together. This mainly involved putting together two big parts, which was the pipeline to run the segmentation model -> generate 2D occupancy matrix -> path-planning -> haptic feedback with the pipeline that localizes the person using UWB sensors. The two pipelines are fully robust on their own, but we worked to update the person on the occupancy matrix using UWB sensors instead of mouse presses. This also involved communication between the Raspberry Pi which controls all the components on the belt with the processing node (in this case our laptop for now) which runs path planning on the occupancy matrix and sends the results back.
Alongside this, we also worked as a team to verify and validate our results. Some simple tests that we have done throughout the course of the semester was taking images with the camera and making sure it covers a 6×6 space, validated by markers on the ground. We chose a few rooms on campus to do this test. We tested our occupancy matrix generation by running the segmentation model on all these rooms and noting how well it segments the room into obstacles. Obstacles were definitely detected more than 90% of the time, and with our algorithm to create a conservative bound for obstacles it will definitely be unlikely for the user to collide into obstacles. False positives were also quite rare (when the model detects free space as obstacles), and only happens when there is a glare from the sun or something similar. We tested our entire pipeline by seeing if the person would walk into obstacles given the feedback from our haptic sensors on a variety of environments and configurations of obstacles set up.
Lastly, we also worked on the presentation slides concurrently as we have slides due next week.
Our progress might be slightly behind schedule as we are still waiting on a few components to arrive. We have 4 haptic vibrators, but we need 2 more to complete our system. We are also hanging our UWB sensors on the ceiling, but we would use stands in the real demo.
Next week, we hope to put our entire system together so that we can get ready for demo. We have most of the parts working together but not completely yet. We also hope to get started on final deliverables next week.
As I’ve designed, implemented, and debugged my project, I’ve learned that it is extremely crucial to do thorough research on the internet on what you are trying to implement rather than implementing it from scratch. I think the saying “don’t rebuild the wheel” really applies, because there are so many resources out there where people have already built the same things you are building. Even if it is not exactly the same, the knowledge I gain from that additional research is invaluable and could save me so much time. Using hardware components with clear documentation and a user forum will save me a lot of headache as these systems do not work out the box most times, and would require some debugging.
I also found it extremely useful to unit-test. Since our systems are huge, there could be so many moving parts and it would be difficult to isolate the error. Testing each part incrementally is extremely crucial to the entire implementation working.
Team’s Status Report for 4/12
The most significant risks that could jeopardize the success of our project is the error while overlaying the coordinate system given by the UWB sensors and the coordinate system that we have from the segmentation model. Since obstacles are in one coordinate system and user localization is in another, incorrect overlaying could cause our user to bump into obstacles or never be guided to the right location. This could definitely jeopardize our project working, and is the last main milestone we have to accomplish. To manage these risks, we came up with a calibration system that could recalibrate the UWB coordinate system and scale it to match the occupancy matrix in which we run path planning on. We would have to work on it further to ensure it is fully robust. Another slight risk is that the Jetson does not have enough processing power to run the segmentation model that identifies our environment as obstacles or free space. To manage this risk, we could offload the compute to the cloud or on a separate laptop. Since the SAM model is not exactly tiny or meant for edge devices, the cloud or a working laptop is definitely a better alternative.
Thus, the only possible change that we might make to our existing design is offloading the compute from the Jetson to the cloud or a laptop. This change is necessary because it is quite evident that the Jetson does not have enough processing power or RAM to run segmentation models. We could try troubleshooting this a bit more or consider alternatives, but this is a possible change we might make.
To verify our project starting from the beginning of the pipeline, we would first test the accuracy of the segmentation model. So far we have inputted around 5-6 example images from the bird’s eye view and analyzed how well it was able to segment free space and obstacles. It has done an accurate job so far, but once we are in the verification stage we would empirically test it on 10 different environments and make sure the accuracy is above 95%. For latency of the pipeline on segmentation, we already know it will be approximately 30 seconds. Thus, we would have to slightly adjust our use case requirements to a fixed environment but still monitor the user in real time. The rest of the pipeline has minimal latency (downsampling algorithm, A* path finding algorithm, socket communication between Raspberry Pi and laptop, etc), so the segmentation model is the only bottleneck. We would run it in different environments and note the latency to verify our use case requirements. For correct navigation of the user to the destination, the main concern is the overlay between the coordinate system given by the UWB sensors and the coordinate system given by the segmentation model. Getting the haptics to vibrate in the right direction should not be a huge issue, but the main issue is most likely having the person be at the correct location indicated by the UWB sensors. We can measure this empirically by noting the error between where the person is located and where our system thinks he / she is located. This metric could help guide us to the navigation accuracy metric.
Talay’s Status Report for 4/12
This week, I worked on setting up the Arducam wide-lens camera on the Jetson, setting up the keypad to work on the Raspberry Pi, setting up the haptics sensors to work on the Raspberry Pi, and setting up socket communication under the same wifi subnet between the Raspberry Pi and my laptop. The first task I did was setting up the Arducam wide-lens camera by installing the camera drivers on the Jetson. The process was quite smooth compared to the OV2311 Stereo Camera since this wide-lens camera relied on the USB protocol which is a lot more robust.

From the image you can see the quality is decent and the camera has a 102 FOV.
Next I worked on communication between the Raspberry Pi and the laptop using sockets. I set up a virtual environment on the Raspberry Pi and installed all the necessary dependencies to set this up. After this I set up the keypad on the Raspberry Pi using GPIO pins. Once the Raspberry Pi detects that a key is pressed, it sends data to the laptop which runs the A* path planning module and has the occupancy matrix visualized. The keypad is able to select different destinations on the occupancy matrix via network connection.
Once the laptop runs path-planning and determines the next move for the user, it sends the directions back to the user (Raspberry Pi) through the same socket connection. I then set up the haptic vibration motors which is also on the Raspberry Pi. I had to use different GPIO pins to power the vibration motors since some pins were already used for the keypad.
The Python code on the Raspberry Pi was able to detect which direction the user had to move in next and vibrate the corresponding haptic vibration motors. Our haptic vibration motors had slightly short wires, so we might need an extension for the final belt design.
I believe my progress is on schedule. Currently, the next main milestone for the team is to integrate the UWB sensor localization with the existing occupancy matrix. This is our last moving part in terms of project functionality. The last milestone for this project would be to integrate the Arducam wide-lens camera instead of the phone camera.
Next week, I hope to work with Kevin on integrating the UWB sensor localization with the occupancy matrix generated from the segmentation model and down-sampling. Currently, the user location is simulated through mouse presses, but we want it to be updated on our program through data received from the UWB tags. We would have to think about the scale factor of the camera frame and how much it has been downsampled, and apply the same scale to the UWB reference frame.
To verify my components of the subsystem, I would first test the downsampling algorithm and the A* path-planning module on different environments. I would feed the pipeline around 10-15 bird’s eye view images of indoor spaces. After the segmentation model, I would note if the downsampling does a good job of retaining the required resolution and identifying obstacles and free space. I would empirically measure the occupancy matrix on whether 95% of obstacles are actually still labeled as obstacles. To meet our use case requirement of not bumping into obstacles, I would come up with a metric that shoots for over-detection of obstacles rather than under-detection. Our current downsampling algorithm creates a halo effect around the obstacles, which would meet this requirement. For the communication requirements between the Raspberry Pi (the user’s belt) and the laptop, there is already minimal processing time. The A* path planning algorithm also has minimal processing time, so the user will have real-time updates on which direction to go through haptic sensors that meets our timing requirements. For percentage of navigation to the right location, I would check whether the haptic sensors always vibrate in the right direction out of 10 tries. If there is some calibration required by a compass, that would be taken into account as well.
Team’s Status Report for 3/29
The most significant risk that can jeopardize the success of the project is the overlay between the coordinate plane given by the camera and the coordinate plane given by the UWB sensors. Right now, we have an occupancy matrix of all the obstacles in the indoor environment. We got the basic functionality of the UWB sensors working but to localize the person with the UWB tag in the same frame we would need to overlay the two coordinate planes on top of each other. Since the occupancy matrix is downsampled by an arbitrary scale, we would need to calibrate the UWB sensors so the user’s movements are accurately reflected on the occupancy matrix. We believe this is the next main complexity of our project that we would need to tackle. With 4 UWB sensors (including one on the person), we would be able to localize the person in 3D space. Since our occupancy matrix is 2D, we would need some to use some geometry to match the movements of the person onto the grid. Since the camera used is a 120 degree FOV, we would also need to account for some warping effects on the sides. Once we have all 4 UWB sensors, we can definitely try to test that out.
Another risk that could jeopardize the success of the project is the compute power of the Jetson. Our current software pipeline is already taking a few minutes to run on the laptop, and we still have the UWB positioning left. Once we complete our pipeline, we were planning to move the processing to the Jetson. If the Jetson is unable to process this in a reasonable time, we may have to consider a more powerful Jetson or doing our processing on the laptop.
Some minor changes to the design of the system is that the destination selection will be fully configurable by the user now. When setting up the environment, the user will have the option to configure what locations they would like to request navigation to in the future. This will be set up with a UI that a caregiver can use.
Talay’s Status Report for 3/29
This week, I continued working on the path-finding algorithm and fine-tuning it so that it would be best for our use-case. I decided to switch from a D* path finding algorithm to an A* path finding algorithm so that it does not store any state from iteration to iteration. When integrated with the UWB sensors, we foresee that there might be some warping action with respect to the user’s position. D* path planning algorithm uses heuristics to only calculate certain parts of the path, which relies on the user moving in adjacent cells. Because the user might warp a few cells, A* path finding algorithm is more suitable because it calculates the path from scratch during each iteration. I simulated the user’s position on the grid with mouse clicks and there was minimal latency, so we are going to proceed with the A* path finding algorithm.
Next, I tested the segmentation model on multiple rooms in Hammerschlag Hall. The segmentation itself was quite robust, but our processing to further segment the image into obstacles and free space was not quite robust. I revisited this logic and tweaked a few points so it selected the largest segmented space as free space and everything else as obstacles. Now, we have a fine-grained occupancy matrix that needs to be downsampled.
I worked on the downsampling algorithm with Kevin. We decided to downsample by picking chunks of certain size (n x n) and labeling it as an obstacle or free space (1 x 1 block on the downsampled grid) depending on how many blocks in the chunk were labeled as obstacles. We wanted a conservative estimate on obstacles, so we wanted the obstacles to have a bigger boundary. This way, the blind person wouldn’t walk into the obstacle. We did this by choosing a low voting threshold within each chunk. For example, if 20% or more of the cells within a chunk were labeled as obstacles, the downsampled cell will be labeled as an obstacle. Once we downsampled the original occupancy matrix generated by the segmentation model, we saw that the resolution was still good enough and we got a conservative bound on obstacles.

This is the livestream capture from the phone camera mounted up top.

This is the segmented image.
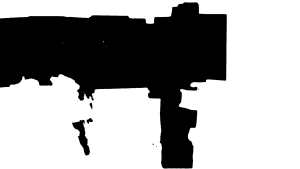
Here, we do processing on the segmented image to label the black parts (ground) as free space and the white parts as obstacles.
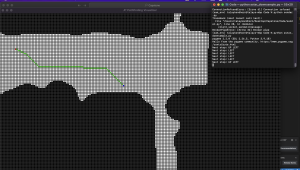
Here is the A* path finding algorithm running on the downsampled occupancy grid. Here, the red is the target and the blue is the user. The program outputs that the next step is top left.
I believe that our progress is on schedule. Next week, I hope to work with the team to create a user interface where they could select the destination. The user should be able to preconfigure which destinations they would like to save in our program so that they can request navigation to that location with a button press. I would also like to try to run the entire software stack on the Jetson to see if the Jetson can process everything with reasonable latency.
Team Status Report for 3/22
The most significant risk that can jeopardize the success of this project is the UWB sensors not working as well as we expected. Our software pipeline is decently robust at this point, however, we are completely relying on the UWB sensors embedded on the user’s belt to determine the user’s location and update it on the D* Path Planning algorithm. The frame captured from the phone camera and the frame calculated from the UWB sensors might also have different dimensions, so the movements of the person may not completely align on the occupancy matrix we run path finding on. This misalignment could cause significant drift as the user moves and makes it difficult to guide him to the target.
These risks are being mitigated by having some of our team members look into libraries that could decrease the fish eye effect on the ends of the image. Since we needed wide lens camera to capture the entire frame, warping on the ends is something that we need to work with. Since our UWB sensors most likely would work uniformly throughout, it would probably be easiest to decrease warping from the CV pipeline.
Another risk is the compass orientation we receive and how we are going to integrate that with the D* path finding algorithm. Since these components take some time to arrive, we can currently work on the software stack right now. However, we are looking into drivers and libraries that could run these hardware components.
There are no changes to our schedule. This week, our main milestones were getting some sort of camera to work and send feed to the computer processing the data. We were also able to select a segmentation model that could classify free spaces and obstacles. Our D* Path Planning algorithm is mostly working, and we will focus on integration next week.
Talay’s Status Report for 3/22
This week, I first tried to find an alternate to the OV2311 Stereo Camera that was not working with the Jetson. The camera had some issues and so we decided to use a phone camera that would be sent to the laptop for processing. We are going to move forward with this solution for the time being so that we can get to MVP and then decide to tweak some of the components later. I was able to capture images from my phone camera’s wide lens view and receive it on my laptop using Python’s OpenCV library. The frame of the indoor environment being stored as an OpenCV video capture is perfect for us to process later.

After this, I tried to experiment with some CV segmentation models that could classify the environment into either obstacles or free space. The models I tried were Segment Anything Model (SAM), Mask2Former Universal Segmentation, DeepLabV3 with COCO weights, and DeepLabV3 with Pascal weights. These models are pre-trained with mostly general data, and so they did not work as well on indoor environments from a top-down bird’s eye view as seen in the following images.
SAM Model With Hamerschlag Hall View:

SAM Model + Mask2Former Universal Segmentation:

DeepLabV3 Model with COCO Weights:

DeepLabV3 Model with Pascal Weights:

As seen from these images, the closest model that is able to at least outline the edges of the furniture is the SAM Model. Charles was able to tune the model such that it fills in the entire furniture and so we were able to get a working model from that. Thus, we are now going to base our segmentation model on the modified SAM Model.
Next, I started working on the D* Lite algorithm. I was able to create a UI that displays the person and the target in a 2D occupancy matrix (one that is similar to the one generated from the modified SAM model). The 2D occupancy matrix contains 0 for free space and -1 for occupied space. The D* algorithm recalculates the shortest path starting from the target to the person and uses heuristics to speed up the algorithm. Currently, I am controlling the person using arrow keys but these will be replaced with UWB sensors after we get that working. The person will also be navigated in the direction of the lowest cost.
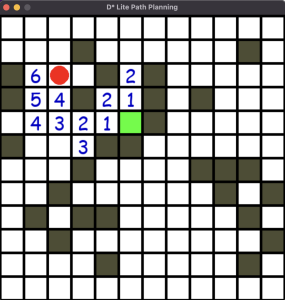
My progress is slightly behind schedule as we were not able to get the OV2311 camera working. However, we have decided to use the phone camera as an alternative so we can move forward with our project. Once we have a working model for all the parts, we can consider switching back to the stereo camera instead of a phone camera. With the phone camera working, we are able to make significant progress on the software end of our project this week, so we expect similar progress going forward.
Next week, I hope to integrate the phone camera, SAM CV Model, and D* Lite Path Planning algorithm all into the same pipeline. Currently, these are all working as lone components, but we have to ensure that the output of one stack can feed into the input of the other. Once I am able to integrate all these components, our software stack will be mostly done and we could plug in hardware components as we move forward.