
This week I spent a lot of time on the CV part of our project. The first challenge of this week was finding a model that could effectively recognize objects. This immediately came with some shortcomings, a lot of the object recognition models are not trained on images that are taken from a top-down POV. This lead to some very questionable predictions and a lot of times omitted larger portions of the image. I’m still not really sure why parts of the image were not inferred on or if they was just not guess for an object. The picture below shows one of the inferences:

There wasn’t that much of a solution to this problem as other models also gave questionable results. I then moved onto a segmentation only model which lowered the model’s complexity and was only used to segment the image. This ended up working much better in terms of pure obstacle detection than the YOLO model. I used the Segment Anything Model from Facebook and it returns masks of segmented objects. I then heuristically chose the largest continuous segmented object to be the floor as this is usually the case. The result of this code is below:
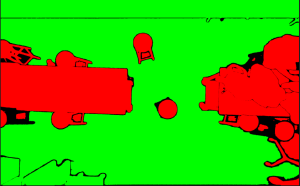
In this image, the green is considered the floor, and all the red is considered an obstacle. As we can see from the image, the results are actually quite accurate. I also converted this image into a occupancy matrix, preparing the data for pathfinding afterwards.
Assuming that this heuristic approach will work for our future rooms, I have started to move towards pathplanning/finding. I am working together with Talay to hopefully implement a working A*/D* algorithm. We hope to first simulate the algo with a controllable character and a prompt telling us the intended route to the target.