Accomplishments
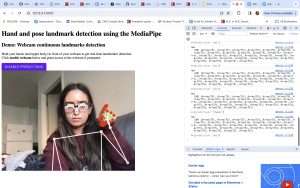
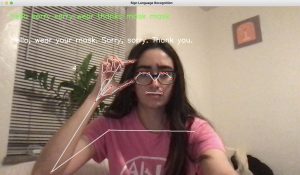
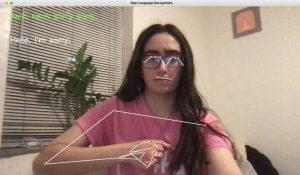
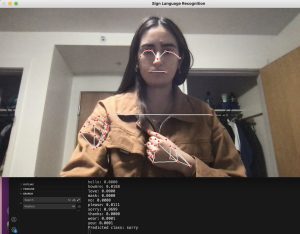
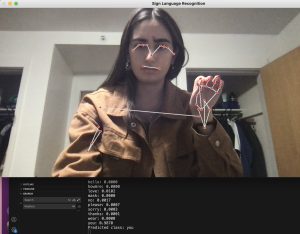
This week, I worked with my teammates on improving the existing web app, deploying, and integrating with bluetooth. Continuing from the progress since last week, we displayed the translated sentence on the HTML page, integrating end of sentence logic and the LLM to structure the sentence. After this, I worked on the frontend UI by adding a home page, instructions page, and our main functionality on a separate detect page, as shown in the images below. I positioned the elements similar to how we originally decided from our wireframes in our design presentation and also included some text for a more seamless user experience. After having some issues deploying our web page with AWS, I tried another method of deploying. However, I am still running into issues with building all the libraries and packages into the rendering.



My progress is on schedule as deployment is the last step we have to complete in terms of the software before the final demo.
Next week, we will complete this, connect with the hardware and work on the rest of the final deliverables.