This week, I worked on fixing the issue with predicting dynamic signs using the trained model. Previously, it would not create an accurate prediction and instead predict the same gesture regardless of the sign. I spent time debugging and iterating through the steps. I attempted to predict a gesture from a video instead of the webcam. I found that it was ~99% accurate, so I found that the issue was related to the differences in frame rate when using the webcam. Fixing this, I tested the model again and found that it was successfully predicting gestures. However, it was predicting accurately only about 70% of the time. Using the script I made for predicting gestures from videos, I found that when I inserted my own videos, the accuracy went down, meaning that the model needs to be further trained to allow recognition of diverse signing conditions and environments. After this, I created some of my own videos for each phrase, and inserted them into the dataset and further trained the model.
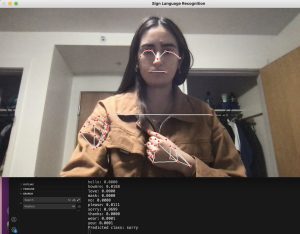
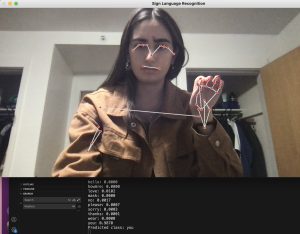
My progress is slightly behind schedule as the schedule said that milestone 3, word translation, should have been completed by this week, but I am still working on improving accuracy for word translation.
Next week, I hope to continue adding to the dataset and improve accuracy of detecting signs. I will do this by continuing to create my own videos and trying to integrate online datasets. The challenge with this is that the videos need to have a consistent amount of frames, so I might need to do additional preprocessing when adding data. Additionally, as we approach the interim demo, I will also be working with Ran and Leia to integrate our machine learning model into our swift application.