This week I spent most of my time outside of classes working with Professor Dueck and her collaborative pianists and singers to collect more flow state data and I also collected focus/distracted data with Karen. I retrained both the flow and focus state models with the new data and re-ran the Shapley value plots to see if the models are still picking up on features that match existing research. Our flow state model is now trained on 5,574 flow data points and 7,778 not in flow data points and our focus state model is trained on 11,000 focused data points and 9,000 distracted data points.
The flow state model incorporates data from 6 recordings of I-Hsiang (pianist), 7 recordings of Justin (pianist), and 2 recordings of Rick (singer). I evaluated the model performance against 3 test sets:
The first one is pulled from data from the recordings used in training but the data points themselves were not included in the training set.
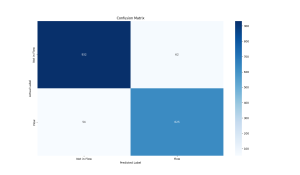
Precision: 0.9098
Recall: 0.9205
F1 Score: 0.9151
The second test set was from a recording of Elettra playing the piano which was not included in the training set at all.
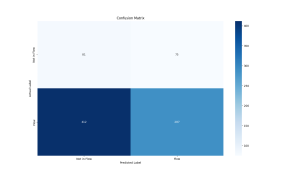
Precision: 0.7928
Recall: 0.4106
F1 Score: 0.5410
The third test set was from two recordings of Ricky singing which were not included in the training set at all.
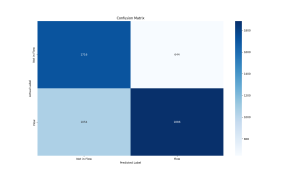
Precision: 0.7455
Recall: 0.6415
F1 Score: 0.6896
The focus state model incorporates data from 2 recordings of Rohan, 4 recordings of Karen, and 2 recordings of Arnav. I evaluated the model performance against 3 test sets:
The first one is pulled from data from the recordings used in training but the data points themselves were not included in the training set.

Precision: 0.9257
Recall: 0.9141
F1 Score: 0.9199
The second test set was from two recordings of Karen which were not included in the training set at all.
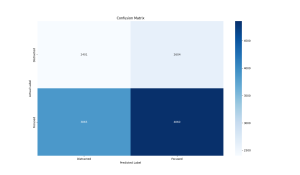
Precision: 0.6511
Recall: 0.5570
F1 Score: 0.6004
The third test set was from two recordings of Ricky singing which were not included in the training set at all.
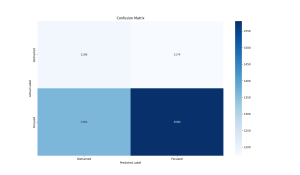
Precision: 0.5737
Recall: 0.5374
F1 Score: 0.5550
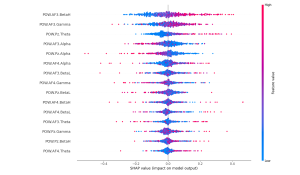
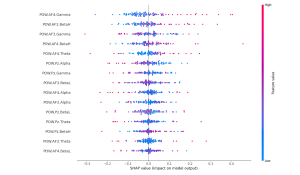
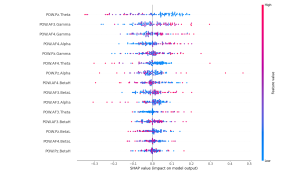
Finally, I reran the Shapley values for both the flow and focus state models and found that the features they are picking up still match up with existing research on these brain states. Furthermore, features that are particularly prominent in flow states such as theta waves are contributing heavily to a classification of flow in the flow state models but is contributing strongly towards a classification of non-focus in the focus state model which is very interesting because it demonstrates that the models are picking up on the distinction between flow and focus brain states.
Flow Shapley values:
Focus Shapley values:
As I have worked on this project I have learned a lot about the field of neuroscience and the scientific process used in neuroscience experiments/research. I have also learned about the classical opera music world and how to do applied machine learning to try to crack unsolved problems. It has been particularly interesting to bring my expertise in computing to an interdisciplinary project where we are thinking about machine learning, neuroscience, and music and how this intersection can help us understand the brain in new ways. The primary learning strategy I have used to acquire this new knowledge is to discuss my project with as many people as possible and in particular those who are experts in the fields that I know less about (i.e. neuroscience and music). I give frequent updates to Professor Grover and Professor Dueck who are experts in neuroscience and music respectively and have offered significant guidance and pointers to books, papers, and other online resources which have taught me a lot. I have also learned what it is like working on an open-ended research project on a problem that is currently unsolved as opposed to implementing something which has already been done before.