New Tools
To properly access and control our cloud database, Redis, we need to use RedisLabs, an online platform for viewing and manipulating database settings, and RedisInsight, a desktop application that visualizes and allows manually changing database data. These tools will also allow us to view statistics about the database, such as latency and number of accesses, which may help with testing speed of service in the future.
In addition, we are planning to use some jQuery libraries to write JavaScript faster and easier. jQuery also works with multiple browsers so our code is compatible regardless of which features does the browser contain.
Risks
As the natural language processing algorithm is developed further, we realized that it is heavily relying on the grammar structure of input sentences to capture the necessary information. The most significant risk is that if our speech recognition system fails to generate grammatically coherent sentences, it will be difficult for the speech recognition and natural language processing subsystems to integrate. To mitigate the risk, we are ready to use the token matcher on top of the dependency matcher to capture key words in the sentences instead of grammar structures.
The risk with regards to the UIs is that some Bootstrap templates we are currently using are unstable. Depending on how well they are maintained remotely, some always work when the pages are loaded while some may not due to the fact that the servers they live on are poorly maintained. Therefore, we are considering using static styling (CSS, SCSS, and JavaScript) only, but the decision is not finalized yet.
Design Changes
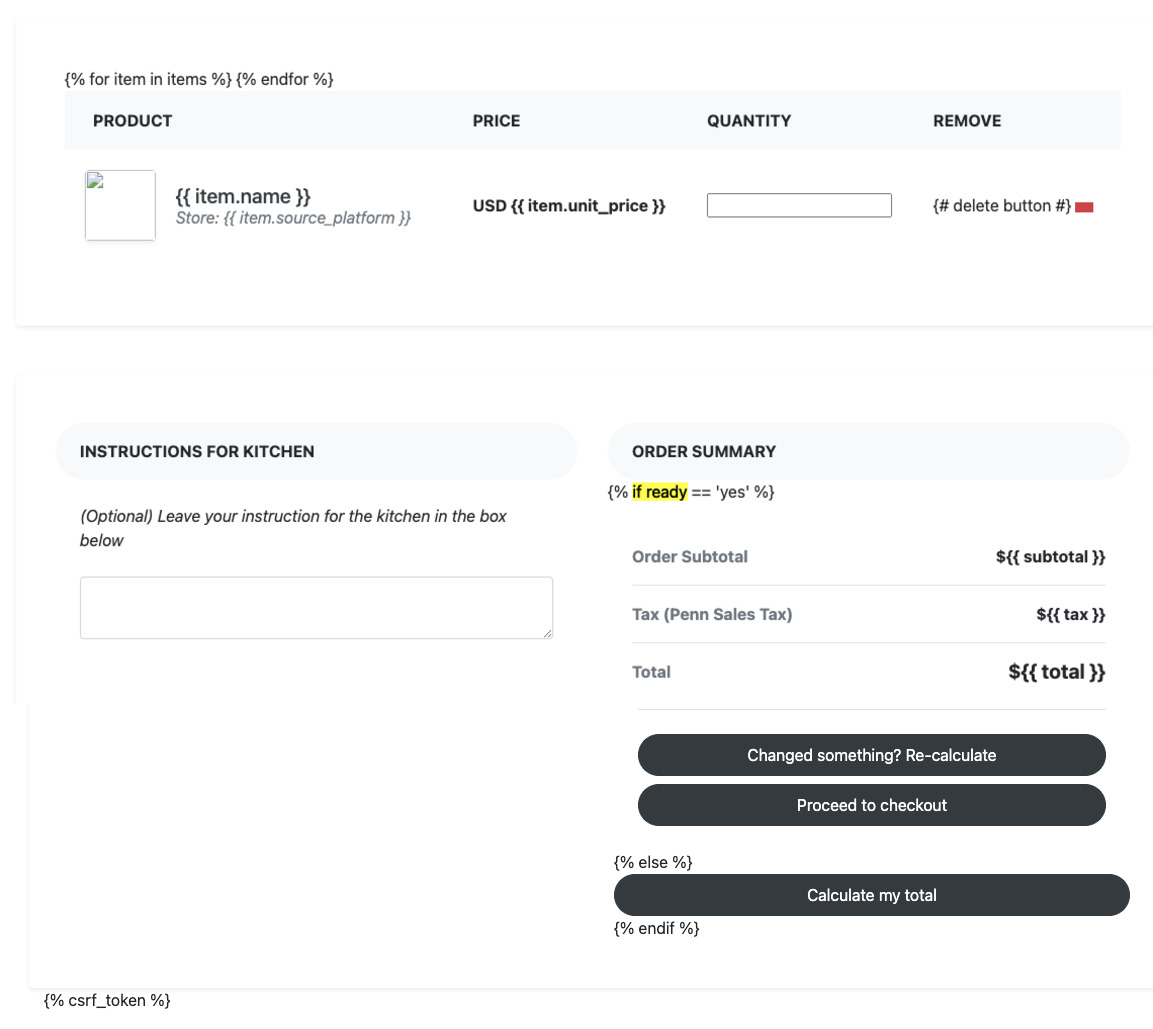
Our design has not changed from our design review report, but we solidified a few design details.
First, we finalized our menu and constructed an immutable dictionary for future use:
cheeseburger $7.99
hamburger $6.99
veggie burger $7.49
chicken burger $7.49
beef sandwich $8.99
chicken sandwich $8.99
hot dog $4.99
corn dog $5.99
taco $6.99
donut $3.99
fries $2.99
onion rings $4.99
fountain drink $1.29
coffee $3.29
ice cream $2.99
For the MVP, we do not plan on allowing customizations or size selections.
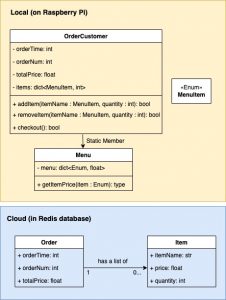
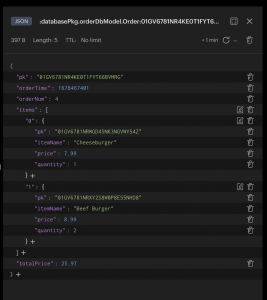
Second, the cloud database and the staff-side module will maintain a server-client-like relationship. When the staff-side module’s subscriber thread receives notification of a new order (sent by the customer-side module when a customer checks out), it requests the order’s information from the database by spawning a child thread. This eliminates the need to constantly poll the cloud database for new data.
Third, we may change how we conduct speech interactions (e.g. near real-time parsing vs. letting customers speak one sentence and then parse) based on how well the noise-reduction and the speech recognition libraries work together.
Schedule
We move the integration between database and NLP to the week after spring break since the MVP version of the two subsystems have just been completed. As a result, the tasks following database and NLP integration have been pushed back as well.