Testing
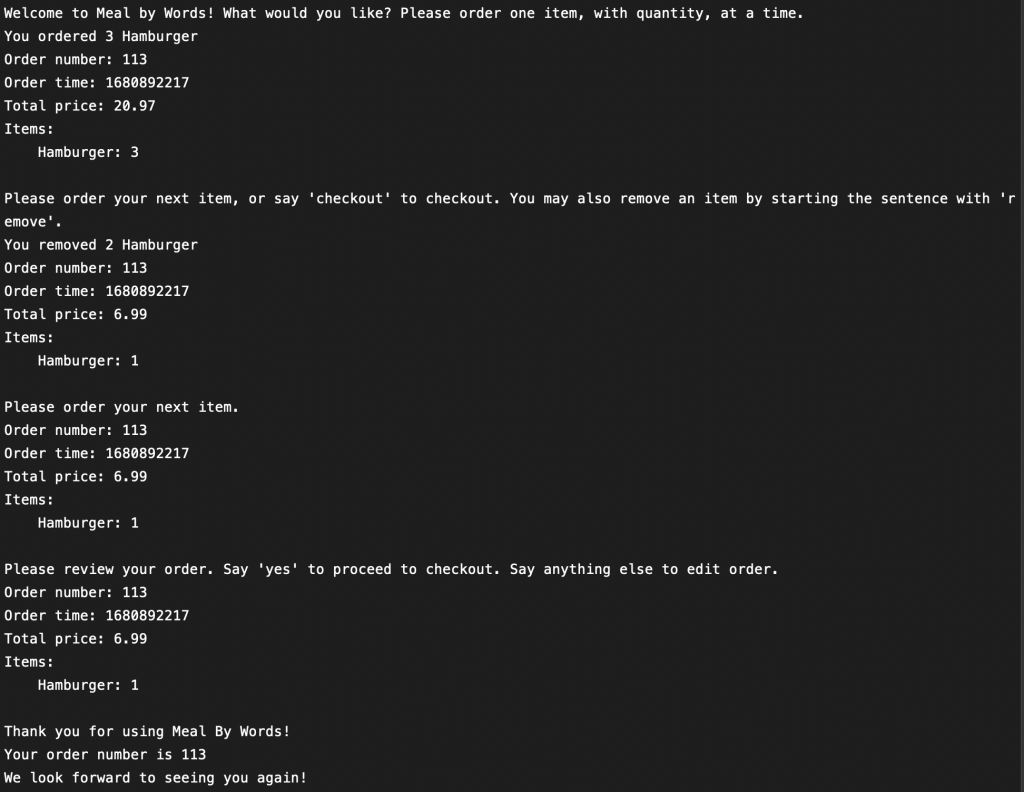
1. Audio to text
Due to the nature of our system, we mainly care that the speech recognition system recognizes the correct word, not its verb tense or singularness. Therefore, verbs of different tenses will be considered as the same word (e.g. “wake,” “Woke,” “waken” are considered the same). Similarly, we won’t distinguish between singular and plural nouns (e.g. “hamburger” and “hamburgers” are considered the same).
The average accuracy across 10 samples was 87.9%. A more detailed report of the test results is available at “Nina Duan’s Status Report For 4/22/2023.”
2. Text to command
We tested the NLP system by sending it text input, simulating the parsed result of the speech recognition system by removing capitalization and punctuations. Some example inputs have already been listed in “Lisa Xiong’s Status Report For 4/22/2023”, and a detailed report will be included in “Lisa Xiong’s Status Report For 4/29/2023”. The NLP system is able to reach 100% accuracy when parsing basic commands.
3. Order upload latency
This tests the latency between the customer-side uploading an order and the staff-side receiving the uploaded order. To calculate the difference, we printed the time when the order was sent and the time when the order was received. “Time” is defined as the amount of time, in seconds, since the epoch (same as how Unix defines time).
The average accuracy across 20 samples, collected over 2 days, was 1.638s. The median was 1.021s. A more detailed report of the test results is available at “Nina Duan’s Status Report For 4/22/2023.”
The latency falls in an acceptable range but fluctuates depending on the latency of the network.
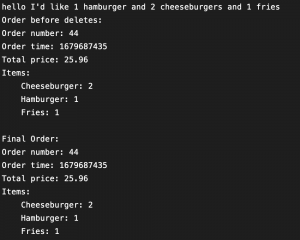
4. Order upload accuracy
This test checks that the order received by the staff-side is the same as the order uploaded from the customer-side. We hard-coded 10 different orders, with varying order items and quantity, and uploaded them to the database.
The resulting accuracy was 100%. We found no mismatch between the order received by the staff-side and the order uploaded from the customer-side.
5. Kiosk activation latency and accuracy
This test checks how long it takes for the distance sensor to detect the presence of an approaching customer. We tested distances including 20 cm, 30 cm, 40 cm, 50 cm, 60 cm, and 80cm. For 20 – 60 cm, the resulting accuracy was 100%. For 80 cm, the accuracy was around 70% but since we are only expecting to detect customers within 60 cm away from the kiosk, we would say we achieved our goal. Latency was always under 2 seconds, and for 93% of time, it was below 1.5 seconds.
6. Latency and accuracy of distance detection for the mic
This test checks how long it takes (latency) for the distance sensor attached to our mic to detect if the person is speaking close enough (25 cm) to the mic when it is their time to speak. In addition, we tested how accurate the results are. For the latency part, it took an average of 1.3 seconds to detect that a customer was not close enough ( > 25 cm). The accuracy rate was 95% on average.
7. Integration test
We have done end-to-end testing among ourselves to make sure that the system is functioning as expected. Our next steps will be documenting the end-to-end order accuracy through thorough tests and finding volunteers to give feedback on the overall design.
Risks
Our entire system depends on the internet. Therefore, if the WiFi at the demo location fails, our system will fail. However, since we are using our laptops to run the system logic, we could use personal hotspots from our phones to keep the system up.
Another risk which we have mentioned in the 4/22 status report is the noise level at Wiegand Gym. We hope that our demo location can be placed in one of the smaller rooms for a quieter environment.
Design Changes
We did not implement any design changes this week. We have finalized our system and are proceeding to the integration/volunteer testing phase of the project.
Schedule
We are on track with our current schedule.