Verification and Validation Plan
Other than running through the entire order workflow (from ordering the first item to checking out) without the UI, which we showed during the interim demo, I’m planning on conducting the following tests:
- Using Python’s built-in function for getting the current system time, measure the difference between the time an order is uploaded to the database after a customer confirms checkout and the time the staff-side UI’s backend is notified of its existence. Ideally, the time should be less than 0.5s (500ms). This will allow the staff-side UI to fetch the data from the database and display the new order in the anticipated 1s latency requirement.
- Verify that the order fetched from the database matches the order the customer placed. All of the following parameters should match: order number, order time, items ordered, and total price.
- Find audio clips with different levels of background noise and play them to the microphone. The speech recognition accuracy should be kept above 85%. This will allow our NLP to recognize menu items most of the time.
After completing each individual test, we will get together as a group and perform some integration tests, preferably with volunteers with different speech habits or from different cultural backgrounds.
Personal Accomplishment
With Lisa’s NLP support, I was able to add a “confirm” functionality to our checkout process. Now, instead of directly checking the customer out when they say “checkout,” the system will ask the customer to review their order. If the customer says “yes,” the system will check them out through the same process as before. Otherwise, the system will return to the previous state, where the customer can add more items or remove existing items.
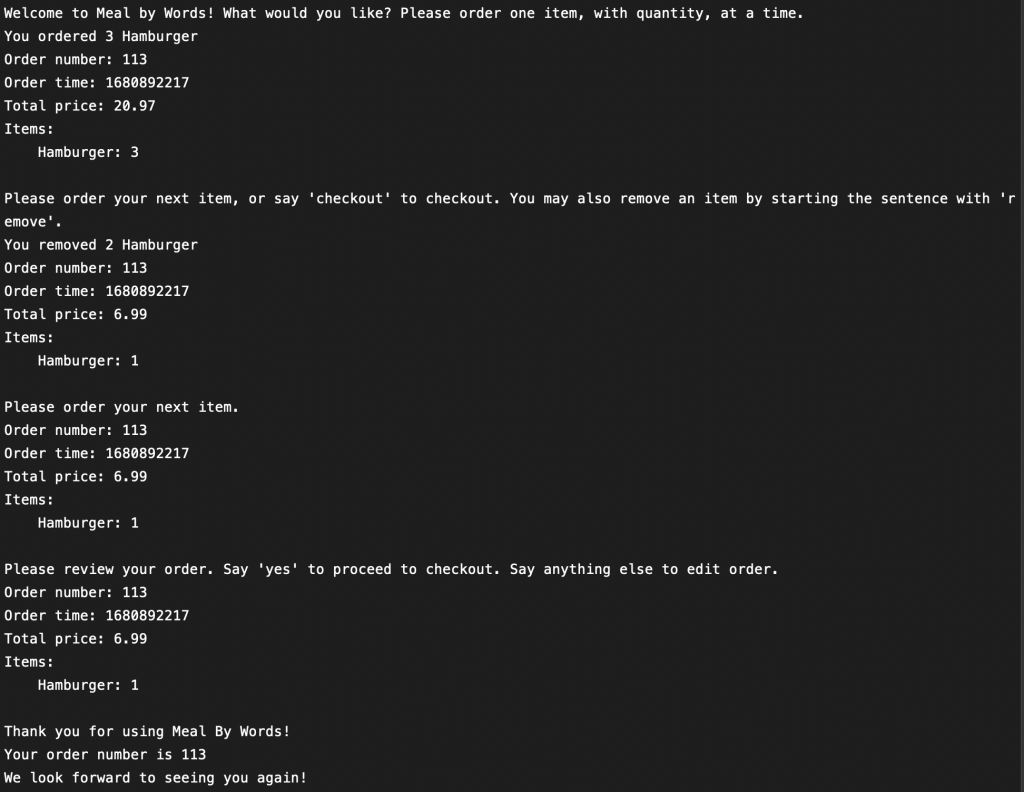
I also fixed a bug in our system that allowed customers to remove items they didn’t order. Before, the system would respond to a “remove” request with “you have removed …” without checking whether the order contains said item. Now, the system will only say so when the customer has, indeed, order the item they desire to remove.
To better support Shiyi’s frontend design, I created a separate thread for indicating when the customer should speak and when they should stop speaking. This thread will be used to control a microphone icon on the customer-side UI. When the system is listening for customer speech, the microphone icon will flash green and invite the customer to speak. Otherwise, the icon will let the customer know that the system is currently unable to hear what they are saying. This long-running thread terminates when the customer confirms to check out, so it can also be used to detect when the checkout process is complete. Therefore, it can also control when the customer-side UI navigates to the “order complete” page.
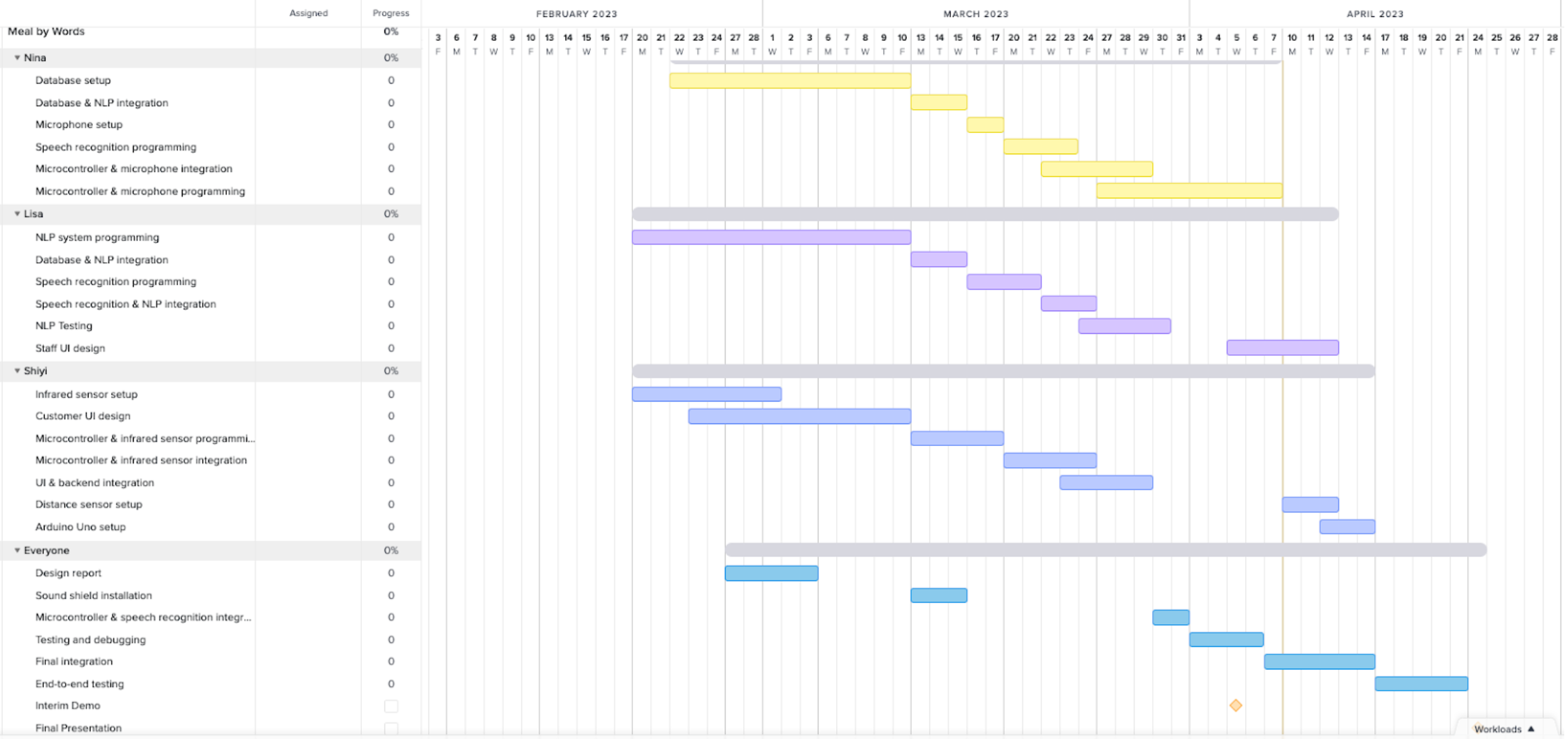
About Schedule
I am on track with the schedule.
Plans for Next Week
I will work with Shiyi to integrate the customer-side UI with the newly edited backend. I will also work with Lisa to integrate the preliminary staff-side UI with the database’s pub-sub functionality. At the same time, I will conduct the tests mentioned in the “Verification and Validation Plan” section.