
Personal Accomplishments
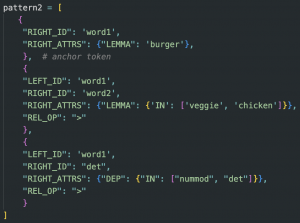
The problem in my NLP system I tried to solve since the last status report is the parsing of menu items with multiple words, as I realized that the dependency parser does not support parsing multiple words as a single token identity. The first solution I came up with was to add all menu items into a list of named entities, so that the NER pipeline can recognize them. However, the menu items could not be considered as named entities in spaCy even when I tried to capitalize the initial letters. Token matching could work, but a lot of flexibility will be compromised when handling varied sentence structures, since the token matcher needs more rigid rules than the dependency matcher. I solved the problem by defining a new set of dependency matching rules for menu items with multiple words. For example, for the menu items “veggie burger” and “chicken burger”, this pattern will use “burger” as the anchor token and find its immediate adjective dependent (either “veggie” or “chicken”) and the quantifier dependent (number or determiner).
The following command line output shows the natural language processing system’s input and output.

For changing item entries, the current solution is to find a set of keywords indicating the change (“remove”, “delete”, “add”, “change”), which should be the immediate head of the menu item token, and change the order information accordingly. The actual ordering situations will be more complex than this scenario, and we plan to fix it after having a functioning system that reaches MVP.
Schedule
I have caught up with the schedule for NLP system programming: a MVP version of the algorithm can be completed by Monday March 13 the latest. Nina and I have not started integrating the database and the NLP system yet; the schedule change is mentioned in the team status report for this week. We did coordinate on what type of data structure the NLP system should return so that the information can feed directly into the database, and I believe the integration should not take long since we already have compatible data structures.
Plans for Next Week
I plan to work with Nina to integrate my NLP system with the database next week. I will also start working on programming the speech recognition system.