
BUILD TOOLS! BUILD TOOLS! BUILD TOOLS!
This week has been an admittedly painful week consisting of setting up all of the configurations for building the Vitis project. As it turns out, setting up the entire build toolchain proved to be a more considerable task than we originally envisioned. The difficulty is figuring out how to interface between the original build tools that the Scotty3D library uses and the build configurations of the Vitis Project itself. (This problem is exacerbated by my complete unfamiliarity with software build tools). The first issue we ran into was that the Scotty3D library requires a version of CMake newer than the version on the ECE number machines. Our plan was to use Vitis on the ECE machines, so this may prove, in polite terms, to be a major annoyance. At this moment, we are still figuring out how to get Vitis and CMake to play nice, but we have hope that we can get past this roadblock soon. One potential solution we’ve been thinking about is to make the vitis project just the fluid simulation kernel and to keep the Scotty3D library mostly as-is, but to have it call the built Vitis project. Either way once we have the build set up, writing some quick performance benchmarking tasks shouldn’t be too difficult.
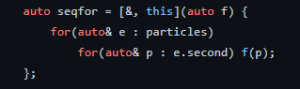
In terms of identifying difficult code chunks, we’ve developed a clearer idea of what needs to be done in terms of refactoring the code for acceleration. First of all, we realized that we would likely have to change some of the formats into a lighter weight and more compact data format for easy data transfer. Then, we realized that we would likely need to manually recreate some of the auto functions in the original code, so as to specifically create non-reentrant versions more specifically optimized for the context of the function call. For instatnce, we would probably want to write separate versions of the seqfor function with differing degrees of loop unrolling.
My next task was cataloguing the hardware resources of the Ultra96v2. From the online manual, we found the following resources:

Of these resources, I want to call specific attention to the number of BRAM blocks and the fumber of DSP slices, as these two elements will likely be a major source of algorithmic improvement. First of all, the large number of BRAMs will allow us to create copies of data and better parallelize the collision-detection task, as we’ll be able to instantly compare against multiple neighbors at once, rather than be forced to wait on resource contention. Then, the DSPs will allow us to perform multiplications and other mathematically-intensive tasks with much better latencies, allowing us to push our clock speeds. Besides these two figures, I think we’ll also have plenty enough CLBs and FFs to implement whatever control logic we’ll need.