Now that we have our mic array and webcam, we can start collecting data. So, this week I worked on creating a testing plan so that we can make a list of what data we need to collect and what parts of the system we need working to collect it. This testing document includes a list of repeatable steps for measuring the accuracy of our speech-to-text output, as well as a list of parameters we can vary between tests (e.g., script content, speakers speaking separately vs. simultaneously, speaker positioning relative to each other and to our device, frequency range of the speech). Many of these parameters I took from my notes on the feedback Dr. Sullivan gave us on our system design when we met with him on Wednesday.
For the sake of collecting test data I also found some videos on YouTube of people speaking basic English phrases (mostly these videos are made for people learning English). We’ll have to test to see if our speech-to-text pipeline performs any differently on live speaking vs. on recorded speaking, but if live vs. recorded doesn’t make a difference, we could use these videos to allow one person to collect 2-speaker test data on their own (which could be easier for us, logistically).
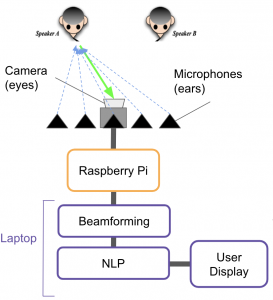
I also helped edit Larry’s Design Review slides. Specifically I changed the formatting of parts of our block diagrams to make them easier to understand, and for our testing plan I combined our capture-to-display delay tests for video and for captions into a single test, since we decided this week to add captions to our video before showing it to the user.
I think we are currently mostly on schedule. Our main goal this week was to hammer out the details of our design for the design presentation. As a team, we went through all of the components of our system and decided how we want to transfer data between them, which was a big gap in our design before this week. We had initially planned to have an initial beamforming algorithm completed by this week, however in our meeting on Wednesday we decided, based on Dr. Sullivan’s feedback, to try and use a linear rather than circular mic array (which affects the beamforming algorithm). Charlie and I will work this week on finishing a beamforming algorithm that we can start running test data through and improving.
In the next week, I plan to finish writing a testing plan for our audio data collection, so that we can log what types of data we need and what we’ve collected, and so we can collect data in a repeatable manner. Charlie and I will collect more audio data and work on the beamforming algorithm so that we can test an iteration of the speech-to-text pipeline this or next week. I also plan to work on our written design report and hopefully have a draft of that done by the end of the week.
In the next week I’ll also try to find a linear mic array that can connect to our Jetson TX2, since we haven’t found one yet.