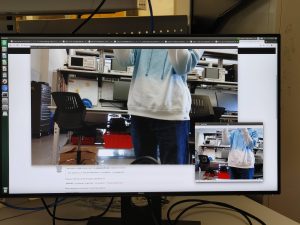
Last week, I spent some time adjusting the caption generation. I wrote a very simple recursive algorithm to have the text move to a new line instead of moving off-screen, though now it can split words in half. I still have to adjust it so that words are not split in half, though that is not a difficult problem.
I also spent time looking over Stella’s final presentation and providing a small amount of feedback.
Another thing I did this week was to integrate the new microphones that we purchased with the scripts that we were running on the Jetson TX2. Surprisingly, we only had to change the sample rates in a few areas. Everything else worked pretty much out of the box. We recorded a lot more data with the new microphones. Here is a good example of a full overlap recording, showcasing both the newer captions and the higher quality microphones:
https://drive.google.com/file/d/1MFlt5AUgrVL5hiOT9XV_zveZVAu-saj3/view?usp=sharing
For comparison, this is a recording from our previous status reports that we made using the microphone array:
https://drive.google.com/file/d/1MmEE7Yh0Kxe5wChuq5n5rHsnGKMOyZYr/view?usp=sharing
The difference is pretty stark.
Currently, we are on schedule for producing an integrated final product. We definitely do not have time for a real-time implementation and we are currently discussing whether we have enough time to create some sort of enclosure for our product. Given how busy the next week will be, I doubt we will be able to do anything substantive.
By next week, we will have completed the final demo. The main items we have to finish are the integration with the website, the data analysis, the final poster, and the final video.