What did you personally accomplish this week on the project? Give files or
photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours).
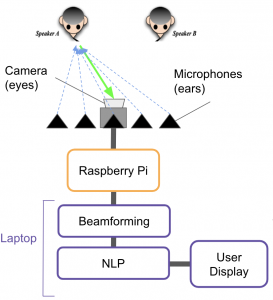
After discussing with my team on Monday, we decided that I would work on a speaker identification problem. In particular, I was trying to solve the problem of identifying whether speaker A is speaking, speaker B is speaking, or both speaker A and B are speaking at the same time.
I originally imagined this as a localization problem, where we try to identify where the speakers are. I tried to use the MATLAB RootMUSICEstimator function, but realise that it requires prior information of the number of speakers in the scene, which defeats the purpose.
Thereafter, I formulated this in the form of a path tracing/signal processing method. Essentially, if only one speaker is speaking, I would expect time delay between the mic closer to the speaker and the mic furthest away. The time delay can be computed by a cross correlation, and the sign of the delay indicates whether the speaker is on the left or right. If both speakers are speaking at the same time, the cross correlation is weaker. Therefore, by thresholding the cross correlation, we can psuedo identify which speaker is speaking when.
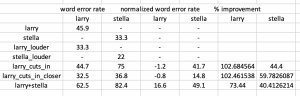
Next, I wanted to follow up on the deep learning approach to see whether conventional signal processing approach can improve the STT predictions. All beamforming methods used are from MATLAB packages. I summarise my work as follows.
- gsc beamformer, then feed into dl speech separation –> poor STT
- gsc beamformer + nc, then feed into dl speech separation –> poor STT
- dl speech separation across all channels, then add up –> better STT
- dl speech separation followed by audio alignment –> better STT
(GSC: Generalised Sidelobe Canceller, DL: Deep Learning, STT: Speech to Text)
It seems that processing the input with conventional signal processing methods is generally weaker at predicting speech. However, applying DL techniques on individual channels, then aligning them could improve performance. I will work with stella in the coming week to see if there is any way I can integrate that with her manual beamforming approach, as I am doubtful of the MATLAB packages implementation (primarily for radar antennas)
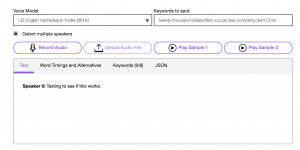
Finally, I wrapped up my week’s work by reformatting our STT DL methods into simple python callable functions (making the DL implementations as abstract to my teammates as possible). Due to the widely available STT packages, I provided 3 STT modules- Google STT, SpeechBrain and IBM Watson. Based on my initial tests, Google and IBM seem to work best, but they operate on a cloud server which might hinder real-time applications.
“ Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
We are behind schedule, as we have not gotten our beamforming to work. Nevertheless, we did manage to get speech separation to work using deep learning, and I have personally been exploring the integration of DL with beamforming.
“ What deliverables do you hope to complete in the next week?
In the next week, I want to be able to get our beamforming algorithm to work, and test its effectiveness. I will do so by meeting Stella more frequently and debug the script together. I also want to encourage my team to start to integrate our camera module with the speech separation module (our MVP), since we do have a workable DL approach right now.