Early this week, I finished fixing the SSF PDCW code in MATLAB so that it runs correctly. I then found the WERs for the speech separated by SSF + PDCW and compared them to the WERs from the deep learning speech separation:
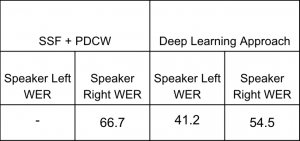
Based on the WERs and on the sound of the recordings, we decided to proceed with the deep learning approach.
This week, we collected a new set of data from two different environments: 1) an indoor conference room, and 2) the outdoor CUC loggia. We collected 5 recordings in each location. I came up with ideas for what we should test before our recording session so we could probe different limits of our system. Our five tests were as follows:
- Solo 1 (clean reference signal): Larry speaks script 1 alone
- Solo 2(clean reference signal): Stella speaks script 2 alone
- Momentary interruptions (as might happen in a real conversation): Stella speaks script 2 while Larry counts – “one”, “two”, “three”, etc… – every 2 seconds (a regular interval for the sake of repeatability)
- Partial overlap: Stella begins script 2, midway through Larry begins script 1, Stella finishes script 2 then, later, Larry finishes script 1
- Full overlap: Stella and Larry begin their respective scripts at the same time
We got the following results:

I ran each of these same recordings through the SSF and PDCW algorithms (to try them out as a pre-processing step) and then fed those outputs into the deep learning speech separation model and then into the speech to text model.
In our meeting this week, Dr. Sullivan pointed out that, since we no longer needed our full circular mic array (instead we now need only two mics) we could spend the rest of our budget on purchasing better mics. Our hope is that the better audio quality will improve our system’s performance, and maybe even give us useable results from the SSF PDCW algorithms. So, on Wednesday, I spent time searching for stereo mic setups. Eventually, I found a stereo USB audio interface and, separately, a pair of good-quality mics and submitted an order request.
This week I also worked on the final project presentation, which I will be giving on Monday.
We are on schedule. We are currently finishing our integration.
This weekend, I will finish creating the slides and prepping my script for my presentation next week. After the presentation, I’ll start on the poster and final report and determine what additional data we want to collect.
This week, we collected a new set of data from two different environments: 1) an indoor conference room, and 2) the outdoor CUC loggia. We collected 5 recordings in each location. I came up with ideas for what we should test before our recording session so we could probe different limits of our system. Our five tests were as follows:
- Solo 1 (clean reference signal): Larry speaks script 1 alone
- Solo 2(clean reference signal): Stella speaks script 2 alone
- Momentary interruptions (as might happen in a real conversation): Stella speaks script 2 while Larry counts – “one”, “two”, “three”, etc… – every 2 seconds (a regular interval for the sake of repeatability)
- Partial overlap: Stella begins script 2, midway through Larry begins script 1, Stella finishes script 2 then, later, Larry finishes script 1
- Full overlap: Stella and Larry begin their respective scripts at the same time
We got the following results:
I ran each of these same recordings through the SSF and PDCW algorithms (to try them out as a pre-processing step) and then fed those outputs into the deep learning speech separation model and then into the speech to text model.
In our meeting this week, Dr. Sullivan pointed out that, since we no longer needed our full circular mic array (instead we now need only two mics) we could spend the rest of our budget on purchasing better mics. Our hope is that the better audio quality will improve our system’s performance, and maybe even give us useable results from the SSF PDCW algorithms. So, on Wednesday, I spent time searching for stereo mic setups. Eventually, I found a stereo USB audio interface and, separately, a pair of good-quality mics and submitted an order request.
This week I also worked on the final project presentation, which I will be giving on Monday.
We are on schedule. We are currently finishing our integration.
This weekend, I will finish creating the slides and prepping my script for my presentation next week. After the presentation, I’ll start on the poster and final report and determine what additional data we want to collect.