
This week, I gave the proposal presentation on behalf of my team. In the presentation, I discussed the use case of our product, and our proposed solution to tackle the current problem. I received some very interesting questions from the rest of the teams. One of my favorites was the possibility to use facial recognition deep learning models to do lip reading. While I doubt that my team will adopt such techniques due to the complexity, it does pique my interest in the topic as a future research direction.
I also designed a simple illustration of our solution, as shown below.
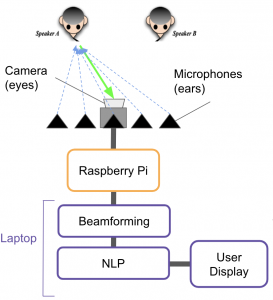
I think my illustration really helped my audience to understand my solution. It is extremely intuitive yet representative of my idea.
After the presentation on Wednesday, my team and I met up in person to work on our design. We decided that the most logical next step was to start working on the design presentation since it will help us to figure out what components we needed to obtain. Nevertheless, we booked a Jetson because we wanted to make sure that Larry could figure out how to use it given that he is the embedded person in our group.
I was also concerned that we might need to upsample our 8kHz audio to 16kHz or 44.1kHz in order to feed into our speech-to-text (STT) model.
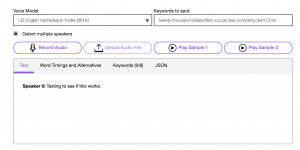
I tested this and made sure that even a 8kHz sampling rate was sufficient for the STT to work.
We are currently on track with our progress, with reference to our gantt chart.
We should be coming up with a list of items we need by the end of this week to submit. Stella and I will start designing the beamforming algorithm this weekend, and Larry will start working on his presentation.