
What did you personally accomplish this week on the project? Give files or
photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours).
This week, I refined my code for the audio component of our project. In particular, Larry wanted me to generate a normalized version of the collected audio, which will be integrated into the video.
The audio component of our project runs on Python 3.8. However, Larry informed me that there were a couple of python dependency errors. In particular, the Speech-To-Text (STT) requires python 3.9, and OpenCV requires 3.7. Python should be backward compatible. Therefore, I was trying to learn how to reset Python on the Jetson. However, we agreed that we should not reset it before the demo day, so that at least we can demonstrate the working components of our project.
For the demo day, I organised my team members and we decided on the list of things we would like to show Professor Sullivan and Janet. Here is the following list I came up with.
Charlie
3 different versions of speech separation of recorded two speakers
– including the predicted speech and WER
Larry
– overlaying text
– simultaneous video and audio recording
– image segmentation
Stella
Gantt Chart
In particular, I wanted to show the WER results of our current speech separation techniques as compared to the baseline. This is an important step to the final stages of our capstone project. The results are summarised below
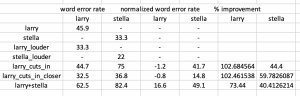
These results show that our speech separation module is comparable to a single speaker speaking (or clear speech), and the largest margin of error arises from the limitations of the STT model. This is a great demonstration of the effectiveness of our current deep learning approach system.
I also did a naive test of how fast speech separation takes on a GPU. Turns out for a 20s audio, it only takes 0.8s, which makes it more realistic for daily use.
“ Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
We are currently on schedule with contigencies. Stella is currently working on the Phase Difference Channel Weighing (PDCW) algorithm generously suggested to us by Professor Stern. We are still hoping to use a more signal processing based approach to speech separation, even though we do already have an effective deep learning approach to compare with.
“ What deliverables do you hope to complete in the next week?
In the next week, I will work with Larry to fully integrate our system. I will work with Stella to see if our signal processing approach is still viable. Finally, upon the suggestion from Professor Sullivan, I want to do a final experiment to get the default WER of our microphone array, simply by having a speaker speak into the microphone array and determining the word error rate from the predicted text.