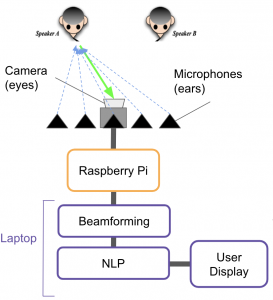
For this first part of this week, I helped Charlie construct his presentation. I also requested and received a Jetson TX2, which we are considering using. The biggest unknown for me is how we plan on capturing and moving around data. We proposed capturing the datastream on the Pi and sending it to a laptop for processing, but doing both on the TX2 would remove the extra step.
I attempted to reflash the TX2 using my personal computer, but I do not have the correct Ubuntu version. Fortunately, the previous group left the default password on, so we could just remove their files and add ours. Space is extremely limited right now without an SD card, so I poked around and preliminarily deleted about a gigabyte in files.
Since the current plan is for me to do the design presentation, I also began looking through the guidance document and structuring the presentation. I should have all of it done by next week.
Overall, I think that I am on schedule or maybe slightly behind. There are still many aspects of the design that need to be hashed out.