
This week was finishing integration and some timing testing. The wrinkle model was integrated into the mirror code, and times were taken with all of the models together ~2.1 seconds for an image. In order to make this number smaller, I change the architecture of the wrinkle model to match that of the acne detection model, causing its individual inference time to go down to ~0.12 seconds. Beyond that, face detection was integrated with the mirror, although we had to switch from blazeface to DeepFace, due to RPi compatibility issues.
Isaiah’s Status Report for 11/15
What did you personally accomplish this week on the project? Give files or
photos that demonstrate your progress. Prove to the reader that you put sufficient
effort into the project over the course of the week (12+ hours)
This week was spent on both finishing integration, and trying to make the current models work more effectively. 3/4 of the models are integrated and benchmarked in time, taking 2.018 seconds on average to analyze one image with the models. Also, work has been done to improve the model’s capabilities to detect more reliably. In particular, a patching system has been implemented to analyze multiple segments of an image.
What’s left is the just adapt the wrinkle model, integrate the face detection, and to finally perform testing and validation
Isaiah’s Status Report for 11/1
What did you personally accomplish this week on the project? Give files or
photos that demonstrate your progress. Prove to the reader that you put sufficient
effort into the project over the course of the week (12+ hours)
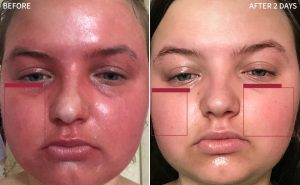
This week I focused on getting the last model ready. I ended up switching to also using a yolo head for sunburn, since it worked well for acne. Likewise, this will need to be fine-tuned to classify what confidence/density would be good for defining “sunburn” vs “no sunburn”. There’s empirical testing that can be done to our >85% accuracy standard, but also some qualitative tuning/testing would be needed, since there’s a gray area between the two binary categories.
Below is one image of the scraped images displayed with burn bounding boxes. The right is more emblematic of typical use cases, but it can detect a burn in both cases.
Isaiah Weekes Status Report for 10/25
What did you personally accomplish this week on the project? Give files or
photos that demonstrate your progress. Prove to the reader that you put sufficient
effort into the project over the course of the week (12+ hours)
A segment of this week was spent on the ethics assignment, but I also put time into training and developing the wrinkle model. This model generates a mask/set of wrinkles, which then can be thresholded to determine skin condition/wrinkle count.
Face image

Wrinkles on face

Testing for a proper threshold for wrinkle count/density will be needed to ensure accurate analysis.
One thing to note is that we are a little off schedule, as we planned to have all four models done, and only three are. This is all still before the building of the mirror, so it’s not acting as a bottleneck, but the sunburn model will need to be done by the end of next week to ensure the project can move forward smoothly.
Isaiah’s Status Report for 10/18
What did you personally accomplish this week on the project? Give files or
photos that demonstrate your progress. Prove to the reader that you put sufficient
effort into the project over the course of the week (12+ hours)
A large amount of time this week was spent with drafting the Design Report. Besides that, a majority of the time remaining was spent training and developing the machine learning models for the skincare analysis. In particular the acne detection model took a large amount of the time. Developing the code for the YOLO used in the acne detection was a more difficult task than I initially thought, although the end results were quite satisfactory. I took guidance from the official YOLO repository, which helped make the process smoother
Here’s a mosaic of detections from the validation set

Since the model is a detection model, I don’t yet have a classification accuracy value yet, but visually the detections look good. Classification would be completed via checking for the presence of acne within a patch, and if it’s there (and with a strong enough confidence), then classifying the patch as having acne. This also gives the ability to have a richer value than just a binary output for acne classification.
The wrinkle detection model is in progress leading likely the sunburn model to be the last one completed.
Team Status Report for 10/4
- What are the most significant risks that could jeopardize the success of the project? How are these risks being managed? What contingency plans are ready?
The most significant risks haven’t changed since last week: it is still making sure our user design is intuitive, and our models are accurate. We developed our physical design a bit more this week, and we discussed what the general flow of the Magic Mirror app should be to ensure ease of use.
In terms of hardware risk, the integration between the new IMX519 camera and the Raspberry Pi 5 introduces potential driver and compatibility challenges. To manage this, we’ve already researched and documented how to bring up the camera using the new picamera2 and libcamera stack. If hardware communication issues arise, our fallback plan is to test using a standard Pi camera first to validate the GPIO and control flow before reintroducing the IMX519. This ensures we can continue development on schedule even if certain hardware components take longer to configure.
- Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)? Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward
One of the only significant changes was adding more buttons to the system for better system control/user experience. We initially decided on having only one button, but as we planned out the app, we realized that navigating it with only one button would be confusing and inconvenient. We have many open GPIO pins on the RPi, and the buttons are still cheap, so this would mainly just affect our physical structure design.
- Provide an updated schedule if changes have occurred.
No changes to the schedule as of now.
Isaiah’s Weekly Status Report for 10/4
What did you personally accomplish this week on the project? Give files or
photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week
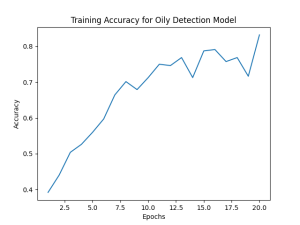
I went back and updated the oily model as described in last week’s report, and I had found successes. The model had learned and performs well on the test dataset. The model achieved at best 87% test accuracy, which is satisfactory. Also, the validation was done with noise added, so the true accuracy might be slightly higher. As such, I moved on to the acne detection. At first, I tried a similar method, but didn’t find much success. I then decided to do more research, and found that both my dataset, and many existing methods do acne detection (generating bounding boxes for acne). So, I decided to start developing an acne detection model, and just the presence or absence of acne to classify any given face. That is in the works as I write this.

Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
What deliverables do you hope to complete in the next week?
Progress is on schedule, I have 1 model done, likely the hardest, and another model that will be done soon. This leaves next week and fall break for training the last two models. Wrinkles will likely be tackled in a similar manor to acne as a detection problem.
Isaiah Weekes’s Weekly Status Report for 9/27
What did you personally accomplish this week on the project? Give files or
photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week
Then, I got started training the model for the oily/normal/dry condition. This task proved challenging however. First, I trained it on the datasets I collected last week, however, the loss was bad, and the model was overfitting with only ~38% validation accuracy. This indicates its only barely better than random. I attempted a couple remedies.
First, I attempted to modify the classification head’s architecture. Namely, reducing the hidden layer sizes, and reducing the number of layers. This only had a marginal effect on the accuracy.
Next, I attempted to test out other models. specifically MobileNetV2, and ResNet, and I got similar results. This indicates that the issue is likely with the data I have. From there, I attempted data augmentation. Each image was color jittered, randomly flipped, and rotated. This would in theory improve regularization. The result was similar however. This indicated that I either needed much more data, or to change the approach.
After looking into more approaches, I found this paper:
Sirawit Saiwaeo, Sujitra Arwatchananukul, Lapatrada Mungmai, Weeraya Preedalikit, Nattapol Aunsri, Human skin type classification using image processing and deep learning approaches, Heliyon, Volume 9, Issue 11, 2023, e21176, ISSN 2405-8440, https://doi.org/10.1016/j.heliyon.2023.e21176 (https://www.sciencedirect.com/science/article/pii/S2405844023083846)
In the paper, the team uses images from close up patches of skin to classify oily/dry/normal. Furthermore, they use an architecture similar to MobileNet, with much, much less data to achieve 92% accuracy. This approach would be doable without changing anything in our physical design, so it was my target. This did result in the camera gaining a new requirement: The resolution of the camera had to be high enough to capture rich details in a 224×224 patch (standard vision model input size). The lowest standard resolution that would fit this (assuming a face takes up ~60% of the image frame) would be about 12MP.
I then checked over the other datasets to make sure they were compatible with patching/appropriate for it, and the acne and wrinkle datasets looked similar in zoom/image size to the dataset the paper used, so no modifications were needed. This also meant that I could re-introduce the burn dataset from before, as that dataset has burn patches that could be used, alongside the scraped images.
Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
What deliverables do you hope to complete in the next week?
This week, the schedule was just to pretrain the models, and finalize camera + processor decisions. This change in my approach doesn’t take me off of schedule, but it does mean that this next week will be pivotal in making sure this part of the project stays on course. It’s also a possibility that some individual metrics take different amounts of time/effort to get well-performing models of. Acne and sunburns are very distinct visual features, and the wrinkles dataset is quite large and comprehensive, so it is likely that oily/dry skin is the hardest task.
(Link to training graph)
https://drive.google.com/file/d/1QYQX7UeJfLUXG3gD1P8TnrqGQmz24VPU/view?usp=sharing