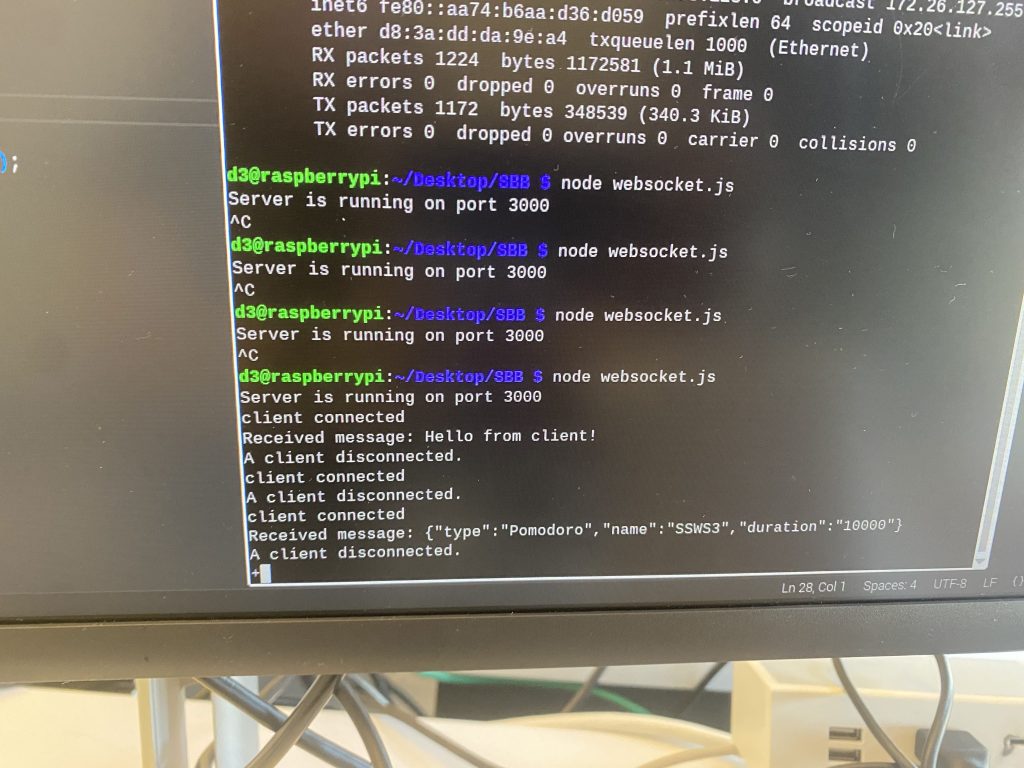
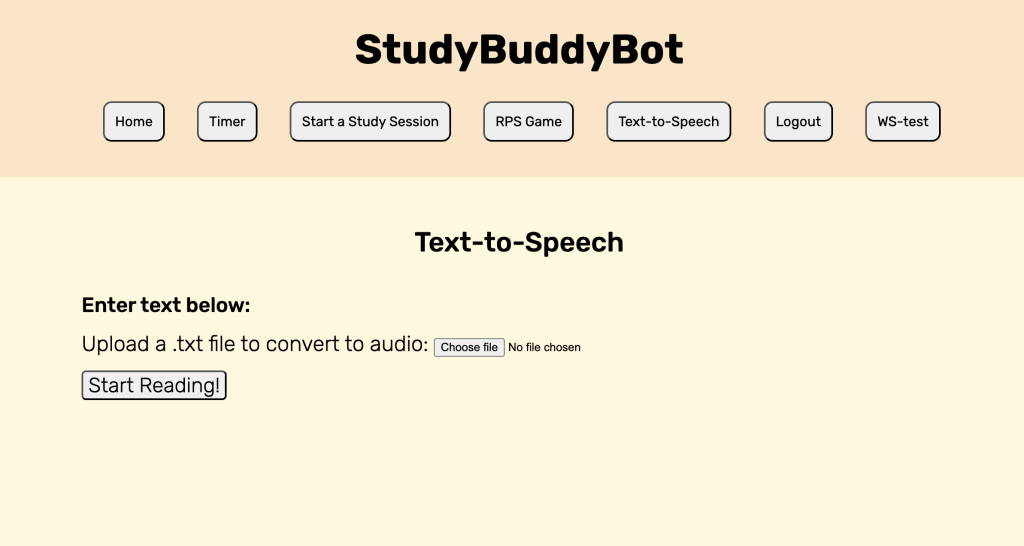
This week, I focused on finishing up the TTS feature on the robot. Since the feature works well on the WebApp, I decided to integrate it fully with the robot’s speakers. I first ensured that the user’s input text could be sent properly via WebSockets to the robot. Once this was achieved, I then used the Google text-to-speech (gTTS) library on the RPi and had it translate the text into a mp3 file. Then, I tried to have the mp3 file play through the speakers. On my personal computer (a macbook), the line to play audio is os.system(f”afplay {audio_file}”). However, since the RPi is a linux system, this does not work and I tried using os.system(“xdg-open {audio_file}”) instead. This allowed the audio file to be played, but also opened up a command terminal for the VLC media player, which is not what I wanted, since the user would not be able to continue playing audio files unless they quit the terminal first. Thus, I had to look up ways to play the audio file and this led me to using os.system(f“mpg123 {audio_file}”). It worked well, and was able to play the audio with no issues. I timed the latency and it was able to be mostly under 3s for a text with word length of 50 words. If the text was longer and was broken into 50 word chunks, the first chunk would take slightly longer, but the subsequent chunks would be mostly under 2.5s which is in line with our use case and design requirements. With this, the text-to-speech feature is mostly finished. There is still a slight issue where for a better user experience, I wanted the WebApp to display when a chunk of text was done reading, but the WebApp is unable to do so. After some debugging, I found that it was because the WebApp tries to display before the WebSocket callback function has returned. Since the function is asynchronous, I would have to use threading on the WebApp if I still want this display to appear. I might not keep this slight detail because introducing threading could cause some issues and the user should be able to tell when a chunk of text is done reading by the audio itself. Nevertheless, the text-to-speech feature now works on the robot, the user can input a .txt file, the robot will read out the first x number of words and then when the user clicks continue, reads out the next x number of words and so on, so I think this feature is final demo ready.
According to the Gantt chart, I am on target.
In the next week, I’ll be working on:
- Helping Jeffrey finish up the Study Session feature
- Finishing up any loose ends on the WebApp (deployment, code clean-up, etc.)
For this week’s additional question:
I had to learn how to use the TTS libraries such as pyttsx3 and gTTS. I thoroughly reviewed their respective documentation at https://pypi.org/project/pyttsx3/ and https://pypi.org/project/gTTS/ to understand how to configure their settings and integrate them into my project. When debugging issues, I relied on online forums like Stack Overflow, which provided insights from others who encountered similar problems. For example, when I encountered the run loop error, I searched for posts describing similar scenarios and experimented with the suggested solutions. It was there that I saw someone recommending gTTS instead, saying how this issue would be prevented because unlike pyttsx3, it does not use an engine and relies on converting text to mp3 files first and then playing instead of converting and playing as it went. This allowed me to switch over to gTTS, which was what we used in the end.
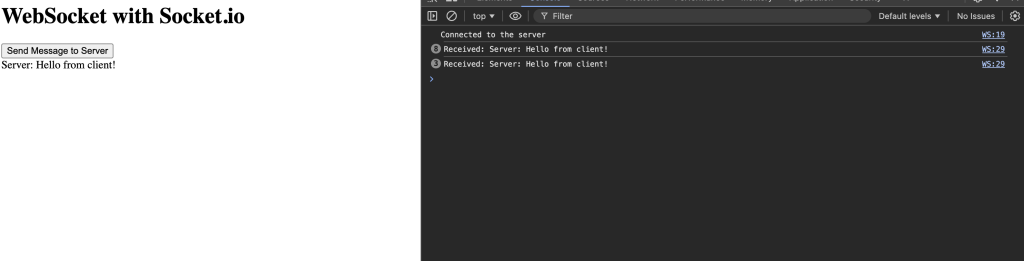
I also had to learn WebSockets for real-time communication between the RPi and the WebApp. I read through the documentation online at https://socket.io/docs/v4/ which was great for understanding how the communication process worked. It also taught me how to set up a server and client, manage events, and handle acknowledgments. For debugging, I used tools that I had previously learnt in other classes, such as the Chrome browser developer tools console and the VSCode Debugger with breakpoints and logpoints, which allowed me to diagnose CORS issues and verify if events were being emitted and if the emitted events were being received through the logs/erros diplayed.