
What are the most significant risks that could jeopardize the success of the project? How are these risks being managed? What contingency plans are ready?
The most significant risks that could jeopardize the success of the project is our color model. The original and quantized color model performs fine on local machines, however the quantized color model performs very poorly on the Jetson. We are still unsure of the specific reason for this since the quantized clothing type and usage models work fine on the Jetson with negligible accuracy losses. We are managing this risk by trying to find the root cause of this issue to make the color model work. If this fails, we will pivot to a new technique which is using the pixel values of the clothing to determine the color. This requires object detection to crop the input photo to just the clothing to prevent extraneous parts of the image affecting the pixel values we evaluate, which has been implemented. The rest of the work just involves predicting a color from the pixel values.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc? Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
No changes were made.
Provide an updated schedule if changes have occurred.
Our schedule has not changed.
This is also the place to put some photos of your progress or to brag about a component you got working.
Photos of our progress are located in our individual status reports.
List all unit tests and overall system test carried out for experimentation of the system. List any findings and design changes made from your analysis of test results and other data obtained from the experimentation.
Classification Tests
For the classification unit tests, the non-quantized models were evaluated using our validation and sanity check datasets. This was done with 3 different trained models for each classification category(ResNet50, ResNet101, ResNet152) to determine which architecture performed the best. Specific graphs for this are located in Alanis’ individual status report, but the best performing architectures were ResNet50 for all the classification models. The validation datasets are 20% of the total dataset (the other 80% is used for training) and produced a 63% clothing type accuracy, 80% color accuracy, and 84% usage accuracy with the ResNet50. The sanity check dataset, which is made up of 80 images that represent the types of images taken by Style Sprout users(laid/hung/worn on a single color/pattern background, good lighting, centered) produced a 60% clothing type accuracy, 65% color accuracy, and 75% usage accuracy with the ResNet50.
We also ran some other tests to determine how lighting and orientation affect the accuracy of the model. This included determining how image brightness, x and y translations, and rotations affect the model accuracies. Graphs and results are located in Alanis’ individual status report.
The findings from the classification unit tests helped us determine the best model architectures(ResNet50) to use. Additionally, since the accuracies on our sanity check dataset did not meet our use case requirements, we changed our design to include a closet inventory page so users could change any incorrect labels to mitigate the low classification accuracy.
S3 Upload Time Tests
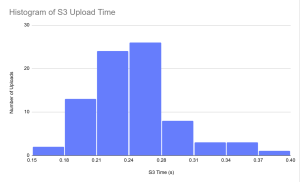
For the S3 upload time tests. We uploaded 80 images to s3 and recorded a timestamp before the upload and took another timestamp after the upload. We took the upload time to be the difference between these two timestamps and the results were overall positive. The upload time was in between 0.15 and 0.40 seconds for the 80 uploads we tested, and the consistency and speed of the upload was welcome news as it allowed us to more reliably ensure our timing requirements for classification. From these test results we determined that no major design changes needed to be made to accommodate S3 image storing.
Database Upload Time Tests
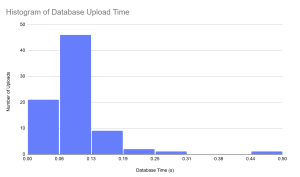
The Database Upload Time was tested much in the same way that the S3 Upload time was tested, by sending 80 images through the protocol and using timestamps to record timings. The results of this test gave an average of 0.09 seconds for database upload, which is well within our use case requirements and doesn’t necessitate a change in our design. There is a slight change between these values and the values I presented. I believe that this is just due to the difference in sending to a server hosted on the same computer and a server hosting on an adjacent computer on the same network. Either way the values fit well within our use case requirements.
Push Button Availability test
Push button availability was tested by pressing the push button 20 times and ensuring that for each of the presses, exactly one image would be taken by the camera. This test passed and we ensured that the pushbutton was successfully integrated into the existing structure.
Jetson Model Accuracy Test
The accuracy of the models were tested on the Jetson with the same dataset that Alanis used as the “sanity check” dataset. On these 80 images we ran the models on the Jetson and got various accuracies and timings. The results we got we in line with the models run by Alanis on her version on tensorflow with the exception of color. We got a type accuracy of 65%, and a usage accuracy of 67.5%. However, when testing the color on the Jetson using the “sanity check” dataset we got an accuracy of 16.25%. When I did manual testing I believe that it was biased towards colors that the model classified better but when we used a dataset that included a larger selection and more even distribution of colors it became clear that the accuracy for color was very low. This necessitated many attempted changed to the model, using different resnet models, saved_models and other methods but the accuracy either remained untouched or it was unfit for our use cases.
Because of this issue, we are looking into a pixel based classification algorithm that would find the average color of a piece of clothing and classify it. We hope that with this method our timing is still acceptable and the accuracy is higher.
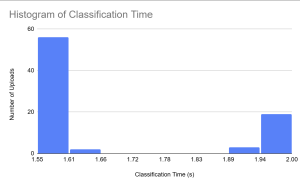
We also obtained data relating to the time that it currently takes to classify each article of clothing. This is only one section of the scanning, as we still need to send to s3 and upload to the database but as we saw with the timings above, even with those timings we are below our use case requirement of 3s (average of 1.69s). (I want to mention that there is a small delay in the process not included in these timings, which is a 1.5s delay that displays the picture that the users took and sent. This is to allow the user to correct any errors that might have occurred for the subsequent pictures).
With this timing data, the timing data for s3, and the timing data for uploading it to the database we can get the average time for the total process not including delays for the user to prepare their clothing. And we determined that the average time was 2.03s for the entire process, which is well below our use case requirements of 3s.
Outfit Generation Speed Test (Backend/Frontend integration test)
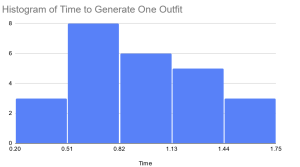
The outfit generation speed test was done by timing how long it took from pressing “Generate Outfit” to the outfit being displayed on the app. We did 25 trials. The longest amount of time it took for generation was 1.7s and the average was 0.904s, both of these are below our use case requirement of 2s.
Frontend/Backend Tests
We tested the functionality and safety of our settings popup page by ensuring that when users update the setting for how many times a piece of clothing can be used before dirty, and their location setting the new values they provide are validated. Validation is done both on the frontend and the backend for the uses before dirty. Validation for location is only done on the backend, and it works by calling the Open Weather Map API to see if the location exists. If either input is flagged as invalid in the backend, we send an exception to the frontend, which then displays an error message to the user to alert them that their inputs were invalid. Both inputted fields must be valid for the update to go through.
We tested the functionality of our generate outfit page by ensuring that all outfits are generated “correctly”, clicking the generate outfit button causes new outfits to appear, clicking the dislike button updates the disliked outfit table in the database and causes a new outfit to appear, and clicking the select outfit button updates the number of uses for all items in the outfit, updates the user preferences table in the database, and brings the user back to the home page. If an outfit is generated, but there is not enough clothing available to generate one then a message will be displayed to the user that they need to scan in more clothing or do laundry to generate an outfit for this request.
A correctly generated outfit is defined below:
- Cold Locations: Includes 1 jacket (if the user has an available jacket). May include a sweater, cardigan, etc (if the user has them available, with some chance). Always has a top/bottom outfit OR one-piece outfit (no shorts or tanks).
- Neutral Locations: Excludes jackets but may include sweaters, cardigans, etc (if the user has them, with some chance). A top/bottom outfit OR one-piece outfit is also always returned.
- Hot Locations: A top/bottom outfit OR one-piece outfit is always returned. No sweaters, jackets, hoodies, etc are ever returned.
- All clothing items generated in outfits must match usage type (casual/formal) and be clean.
We tested the functionality of the privacy notice feature by ensuring that users who have not accepted the notice will have it on their page and can only use the app’s features after accepting it. We tested that accepting the notice is saved for the user. We also tested to ensure that an error message pops up to alert the user if they try to bypass the notice without accepting it.
We tested the functionality of the laundry feature by ensuring that selecting the “do laundry” button causes all items to be marked as clean on the database. We also tested that when an outfit is generated and selected, that all items in the outfit have their number of uses increased in the database. If this number is higher than the user set value for “number of uses until dirty” this should update the item to be dirty. We also validated that dirty items are not part of generated outfits.
We tested the functionality of our closet inventory page by ensuring that no matter the number of clothing items in the database, at most 6 will appear on each page. We also tested that each clothing item in the database will appear on exactly one of the closet pages. This was done with a 0, 3, 6, 18, and 20 images/entries in the database. We also tested the scrolling functionality by ensuring that users could not scroll before the first page and could not scroll to the next inventory page if there were no more clothes to show. We also tested the popup to change labels by ensuring that if the GET request to get the current labels for an image failed, we would display a relevant error message if we were unable to connect to the backend or if there was an HTTP error in the response form the backend. We did this by making sure that the server was not running so that the frontend could not connect to it and by sending various HTTP error codes instead of the requested labels from the backend to the frontend. We also checked that when the user presses submit after changing the labels, a POST request with the changed labels was sent to the backend and the relevant fields in our database were updated. This was done by changing the labels for different clothes on each page and ensuring that our database was updated with the new labels provided.
We tested the user-friendliness of our app by giving 3 people a background on what our app does and how to use it. We then gave them the app and hardware to use Style Sprout and timed how long it took them to use different features. We also had them rate the app out of 10 based on intuitiveness and functionality. We defined intuitiveness as how easy it was to understand the features, and functionality as how easy it was to actually use them.
For the results of these tests, we met our intuitiveness requirements with an average 9/10. Time-wise we also passed the tests, with all features being doable within 10 seconds. However, we did not meet our functionality requirements and got an average of 5/10. Users explained that they struggled specifically with taking images with the camera, and struggled with centering their clothing in the images, leading to a decreased accuracy for classification. As a result, we are adding both a button and a camera stand to our final product to make this process easier for users. After adding these features, we hope to run this test again.
