What are the most significant risks that could jeopardize the success of the project? How are these risks being managed? What contingency plans are ready?
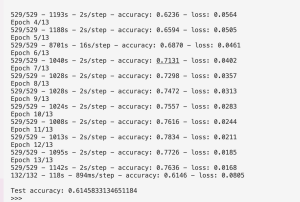
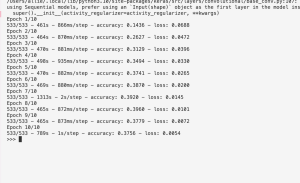
One of the most significant risks that we have identified is the model classification accuracy. Our initial model accuracy that was achieved from a basic image classification neural network structure and no training data manipulation, was about 40%. We are going to augment our dataset by applying rotations, translations, and flipping. We are also going to fine tune our neural network structure to be applicable to our application. If this does not give us a sufficient accuracy, we will use a pretrained model like Resnet50, which we believe is the best option due to its high accuracy and smaller size than other pretrained models like Resnet101. It is also available with Tensorflow, which we are using.
Another risk we identified is storing the images in our database as originally planned. Based on research, it seems like this would not work well because it can lead to a very increased database size and performance issues. This risk is being managed by saving image paths in the database instead, and having the actual images saved on AWS S3. S3 seems to be ideal for our use case because of its scalability, availability and performance, but if this does not work out, we will look into other file storage systems.
As for the hardware side of things, there are no significant risks as the modules and desired functionalities are possible on the Xavier NX. One moderate risk is that the processing speed and RAM capabilities would be too low to properly use the model and potentially host the mobile app. We believe that with the proper optimizations, it should be possible, but one thing that we are doing to mitigate this potential issue is by hosting the mobile app on a server if the speed requirements cannot be met on the Xavier.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc? Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
Because of the risk with storing images in our database, we decided to use the managing plan and are now going to be using AWS S3 to store our images. It will cost $0.023 per GB per month. We aren’t sure how many GB we will need yet, but the overall price should be minimal. Additionally, this change requires moving a few things around in our Gantt chart to have time to integrate AWS S3 to our application.
We changed our image classification accuracy requirements based on our dataset changes. We are now classifying images by clothing type, color, and usage(casual, formal) since these are labels present in the dataset. We want an 80% accuracy for clothing type and color since this will allow us to generate a majority of accurate outfits while giving us a margin of error for sweater vs sweatshirt. We want 70% accuracy for usage type since this is just meant to be something to help us determine the formality of a piece of clothing, we are still focusing on creating predefined outfits and basing formality off of those.
No hardware changes have been made, some aspects were solidified further, such as the Xavier NX and development environment to be used (Ubuntu 22.04)
Provide an updated schedule if changes have occurred.
Alanis has switched the order of two tasks: model training and predefined outfits. The model classification is a much more difficult task and has the possibility of taking longer than the initial week we had outlined, while creating predefined outfits is not a difficult task and time-consuming but not a main priority right now. Our updated Gantt chart is located here.
This is also the place to put some photos of your progress or to brag about a component you got working.
Photos of our progress are located in our individual status reports.
Part A: Written by Alanis
Our product solution is a solution for a problem which doesn’t really fall into the category of public health, safety, or welfare. Style Sprout, solves a “first world problem”, since it provides outfit recommendations with people’s closets, and finding a good outfit in the morning doesn’t significantly impact your physiological/psychological wellbeing, protect you from physical harm, or provision basic needs for you. There are two ways in which Style Sprout minimally relates to public health. Style Sprout shows users various stylish outfits that already exist in their closet. This is done with the intentions of dissuading people form purchasing cheap fast fashion by reminding them about the great clothes they already have. This benefits public health as fast fashion contributes to global warming and pollution, which harms public health. Style Sprout also notifies first-time users about the way in which we use their data, where we will take pictures of their clothing from a camera feed and input them into a machine learning model, which classifies them. One image of their clothing will be stored in our dataset. This notification ensures that users are aware exactly how we use their data in conjunction with artificial intelligence, which could benefit the psychological health of people who are sensitive to the way their personal data is used. We have ensured that our solution does not harm their safety since the Jetson Nano is a small and widely used computer which would not cause them physical harm, just like the camera and light attached to it. We have ensured out solution will not harm people’s basic needs since it does not relate to food, water, shelter, etc. at all.
Part B: Written by Riley
There is a distinct social need for aid in dressing and fashion. Many people wish to dress better or more appropriately and do not have the capabilities or time. Our product solution can address this need by providing an easier way to achieve this with clothing specific to their closet. Most products currently do not provide an easy way to categorize clothing and require uploading of images, something that could form a technological barrier for some. Our design would allow the users to scan in their clothing quicker than alternatives, making it pertinent for users with minimal time due to caretaking.
Another social issue that our product solution could help alleviate is socioeconomic. By focusing on the user’s own closet, it allows them to make more out of their closet than what would otherwise have been possible. This is critical for many families by allowing them to limit their clothing bills which is a large portion of many budgets. By generating outfits whether they be typical or novel, it allows the user to gain inspiration in styling and use of previously underused clothing. By allowing the user to make better use of all their clothing, it limits the desire to expand their wardrobe by providing novel options out of existing pieces. Additionally, by better utilizing their clothing, it spreads wear and tear out among many pieces of clothing, limiting damage, easing repairs and generally extending the lifespan of clothing.
Part C: Written by Gabriella
Our product solution, Style Sprout is designed to help users make full use of their existing closets. This reduces their unnecessary clothing purchases and also encourages fashion sustainability. By simplifying the process of choosing an outfit, our solution helps to combat fast fashion which has terrible economic effects. Additionally, as our application helps to prevent consumers from making unnecessary purchases, not only do our users save money but also the more people use it, the lower the demand for fast fashion becomes.
Economically, Style Sprout helps to make both individual and global impact. For individual users, people benefit by reducing their need to purchase new clothing and it also helps them really get full usage out of pieces they already own. More largely, our app helps to decrease the need for fast fashion overall which can lead to less wasteful consumption of clothing. Finally, our product itself does not create a large economic strain as it uses a camera, cloud storage, and a server. Therefore, Style Sprout helps users be more economically conscious and promotes economic sustainability to individual users, as well as it encourages more mindful fashion consumption overall.