What did you personally accomplish this week on the project?
- Discussion: How should inference be done?
- I spent a significant amount of time this week thinking about the best way to do inference. I had a few ideas:
- Evaluate the model in worker threads in the webserver, as we are doing right now.
- Advantages:
- Less work – already implemented
- The model is small enough to be able to be loaded into multiple processes without issue.
- If the users are only sending images to the server with our provided script, the only side effect is that images get taken less often, to allow the server to process the existing ones.
- “Failure Case – Not enough compute” is not too bad.
- This case would only happen if the user either has ~12 cameras all taking photos at once, or if someone wrote their own script to try to purposely overload the server.
- As we stand, if we get higher image throughput than we have model evaluation bandwidth, the result is not disastrous. Our server currently will just have higher inference latency, and if incoming requests are too old, they will drop. This is not the end of the world, so long as it is not super frequent because a random image is unlikely to be the only one to contain a object to be searched for.
- Disadvantages
- Probably not robust enough for a production server
- Not scalable – the inference will happen on the same machine as the webserver whether we like it or not
- Advantages:
- Create a separate inference server
- Advantages
- Greater control over server behavior
- We can have the serve respond to the client before the image is done processing (no http timeout)
- If we write the server, we will have the ability to globally inspect every element of the image request queue, and have more informed control of which images we drop
- More scalable
- The inference server can go on a separate machine
- If we need more inference power, we can make more inference nodes
- Can give only inference nodes GPUs – webserver nodes should not need GPU
- We have the ability to completely separate the webserver from inference. We could even have the webserver run on the pi, and the inference server run in the cloud, or some mixture of all of the possibilities
- Greater control over server behavior
- Disadvantages
- A lot more work
- Not particularly advantageous for the raspberry pi case – everything will be running on the pi anyways
- Will have to do additional testing to justify creating the server
- Advantages
- Evaluate the model in worker threads in the webserver, as we are doing right now.
- In the end, I think I will keep the inference as-is. It seems like most of the inference server’s advantages come with providing our product as a cloud service, which we don’t seem to be focusing on at this time.
- I spent a significant amount of time this week thinking about the best way to do inference. I had a few ideas:
- Added new model backends
- As shown last week, our model inference is the bottleneck of our webserver. I spent some time this week re-implementing our function that does inference using different backends, notably:
- Ultralytics – Pytorch
- This is the default provided way to do inference on a pytorch model, and was what was implemented previously
- Ultralytics – Onnxruntime
- Ultralytics gives the option to run an .onnx YOLO model. After some googling (google said onnx might be more specialize for inference, etc.), I decided it might be worth trying out.
- Plain Onnxruntime
- I was not sure what Ultralytics does under the hood, and decided it was worth testing a version that simply uses the onnxruntime python package
- Ultralytics – Pytorch
- As shown last week, our model inference is the bottleneck of our webserver. I spent some time this week re-implementing our function that does inference using different backends, notably:
- Additional performance testing
- I also did some work testing each of the aforementioned new model backends.
- Firstly, I made a script that sends several requests to the webserver, and measures the average server-side latency of running inference on an image. On the original ‘Ultralitics – Pytorch’ backend, here is how adding workers doing inference in parallel affects the average inference time of a single request.
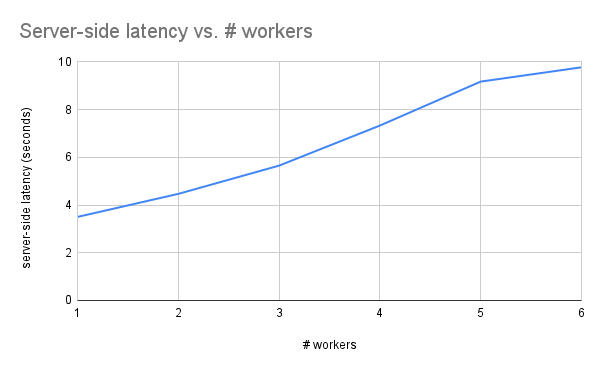
- From this graph we can make two observations:
- Adding workers increases latency. In other words, running inference is either not perfectly parallelizeable. There may be contention over resources between processes, even though there are multiple cores.
- There is still some parallelism to be exploited. The latency for 2 workers is less than twice the latency of running one worker.
- From this, I realized it would be more useful to try to measure the throughput of the computer given different configurations.
- After all, the latency only got worse in the case that all workers are saturated, (in the uncontested case, we always get ~3.5s/img latency regardless of how many workers we spawn) and whether the workers get saturated depends on the throughput of the server.
- Therefore, I made a shell script which sent 10 images to the webserver, and measured how long it took to process them all, from the client side.
- Here are the results for the ‘Ultralytics – Pytorch’ backend:
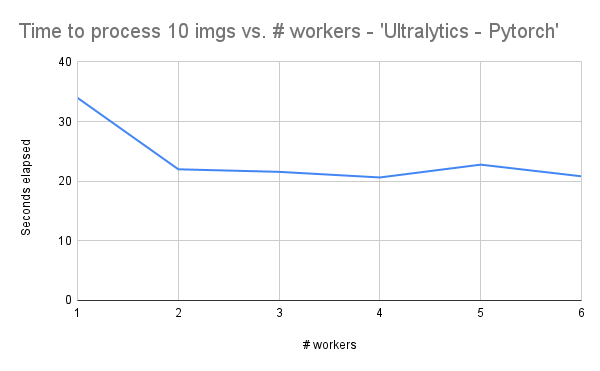
- It seems as though the pytorch backend benefits from having multiple worker processes, but performance levels off after we have 2 processes.
- I then ran the script on the new backends I implemented:
- Here are the results for the ‘Ultralytics – Onnxruntime’ backend:
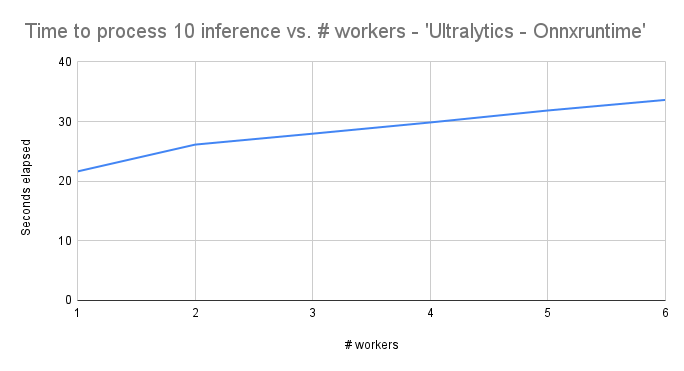
- It seems as though there is no improvement in throughput, but the best throughput happens with a single worker process.
- Here are the results for the ‘Plain Onnxruntime’ backend:
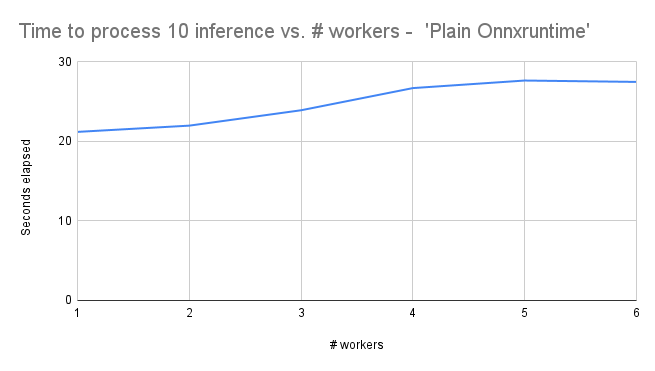
- It seems as though we have similar optimal throughput as the other two backends, but the throughput does not get as bad as the other two backends with increased worker count.
- In summary, It seems like no backend provides a significant optimal performance increase, and we may have to turn to other methods to improve this.
- Continued implementing authentication
- I spent some more time understanding what was necessary to implement authentication, and got a bit further in implementing it, but would still like to add more features in the future.
- I chose to use JWT, as it seems to be well-documented for use with Flask, and seems to provide better control over its useage than Flask-login
- Currently, I have login working. Each user has their images stored in such a way that only one individual’s account is able to access their images. I have also extended the primitive website and helper scripts to use authentication.
- I spent some more time understanding what was necessary to implement authentication, and got a bit further in implementing it, but would still like to add more features in the future.
Is your progress on schedule or behind? If you are behind, what actions will be
taken to catch up to the project schedule?
Given the resources I had access to, I was still able to make some meaningful progress this week. One of my groupmates was sick this week, so we may have to slightly re-evaluate our priorities, though from what I have heard progress is being made regarding the website mentioned last week.
What deliverables do you hope to complete in the next week?
My primary objectives are listed below, but what I actually work on will still be up to some discussion.
- Finishing adding authentication to the server
- I would like to add the ability to log out and delete users.
- Creating “realistic traces” to test the previously mentioned optimizations
- Regarding our discussion about which images we shouldn’t have to store/run the model on, I have yet to make significant progress in that regard. Much of that testing depends on having an existing “realistic trace” of captured images to test the system on. Random training images do not work because many of the cases we are trying to optimize for involve not processing similar images, and if the testing images are all of different settings, the optimizations will do very little. Our lack of such a testing set is primarily a result of the fact that I have had other work due this week, and because I have had some trouble getting ahold of a raspberry pi with a working camera with which I can take the necessary images. I will try to make progress on this objective next week.
- Create optimizations to reduce the number of images to do inference on
- Creating optimizations to bound images stored in the database
- Try to make the inference server faster
- I am not sure whether this will be left to me or Ethan, but we have thought of optimizations such as model quantization, which may make the model run faster.
- I could try to do inference using a pure CPP function and pybind11, but I am doubtful regarding the effectiveness of this optimization. The python implementations already appear to be quite optimized.
In particular, I would like to discuss whether to prioritize having our project perform in a more technologically impressive way
Additionally, I could invest time into adding some of the features mentioned in our proposal, such as the microphone frontend, or porting the server to AWS as a proof of concept.
0 Comments